

Introduction
Research Objectives
Literature Review
Background Study
AOD-Net
DerainNet
Faster R-CNN
Methodology
Data Collection and Preprocessing
Weather-specific image enhancement
Evaluation Metrics
Object Detection Metrics
Results and Discussion
Results
Object Detection Performance
Discussion
Conclusion and Future Scope
Introduction
Autonomous driving and smart surveillance systems depend largely on accurate object detection to assure safety by recognising cars, pedestrians, traffic signals, and other potential hazards [1]. Deep learning has dramatically increased object identification under ideal settings, but performance drops significantly in unfavourable weather (e.g., rain, fog, snow, sand) owing to occlusion, decreased vision, and air interference such as rain streaks and snowflakes [2].
To solve these issues, many ways have been investigated. Numerous methods to increase object detection accuracy have been developed in an attempt to solve the problem of robust object identification in bad weather [3]. Using Real-world datasets with thorough annotations that cover every weather condition to train deep learning models is one such method. Although databases like [4, 5], and [6] provide photographs of a range of weather circumstances, they usually don’t include object annotations for or balanced daylight and all-weather situations images of unfavorable weather. The second choice is to enhance clear weather photos using generative adversarial networks [7, 8], physics- based rendering techniques [9, 10], or a combination of both, as shown in [11], because these datasets are not comprehensive. Each technique has special advantages and disadvantages; for instance, GANs may generate complex noise patterns at the expense of perhaps significantly changing the image content [12]. However, while physics-based techniques lack realism, they maintain visual integrity in noise patterns. For increased accuracy, the third method is to do denoising before object detection. There are numerous image denoising techniques that concentrate on desnowing [13], deraining [14], and dehazing [15, 16]. The performance of current picture restoration methods is subpar in downstream tasks because they are frequently designed based on image quality criteria rather than their effect on detection accuracy.
And also, recent advancements have attempted to completely integrate in order to shorten the gap between detection and restoration processing components. For example, “Image-Adaptive YOLO” trains a differentiable image processing block alongside YOLO to optimise object recognition in bad circumstances [17]. Similarly, D-YOLO combines dual dehazing and detection routes with attention-based feature fusion to improve resilience in foggy conditions, with encouraging results on benchmark datasets such as Foggy City scapes. [18] More recently, UniDet-D combines dynamic spectral attention into a unified restoration- detection model to increase generalisation across many weather types, including unseen combinations like sand-rain mixes.
Building on this trend, we offer a modular two-stage deep learning pipeline designed for adverse-weather object identification. It combines AOD-Net and Derain Net, weather-specific improvement modules, with an adaptive fusion layer and Better R-CNN, a two-stage detection system that’s faster backbone. Unlike many end-to-end solutions that rely simply on one-stage detectors, our methodology takes use of the high accuracy of two-stage designs and guarantees that enhancements contribute directly to detection performance via joint training.
We test our model on the benchmark DAWN dataset, assessing both image restoration (PSNR, SSIM, MSE) and detection performance (mAP, Precision, Recall, IoU), with a focus on class-wise accuracy across various weather circumstances. This focused study fills known gaps in current research, where precise per-class metrics under harsh situations are understudied.
In contrast to current hybrid models like D-YOLO and UniDet-D, which are mostly YOLO-based one- stage detectors with restricted flexibility, the proposed framework presents a modular two-stage pipeline. The model achieves excellent detection accuracy for tiny objects and varying weather conditions by using weather-specific improvement modules (AOD-Net for dehazing, DerainNet for deraining) together with an adaptive fusion layer and Faster R-CNN. This modular approach facilitates end-to-end optimization, whereby restoration immediately enhances detection, resulting in superior generalization across various adverse-weather datasets and enhanced scalability relative to monolithic systems.
Research Objectives
After carefully reviewing the research gaps, the following objectives have been identified to fulfil the aim of this project work:
1.To develop a two-stage deep learning model for robust object detection in adverse weather conditions.
2.To test the performance of the proposed two-stage algorithm using various benchmark datasets.
3.To evaluate the impact of weather-specific enhancement modules (AOD-Net and DerainNet) with adaptive fusion on detection accuracy.
4.To compare the proposed model with unsupervised deep learning approaches for object detection.
Literature Review
A basic problem the field of computer vision, object recognition several uses, including augmented reality, surveillance, and driverless cars. Considerable developments in this field throughout the years have spurred the production of numerous methods meant to increase the precision, effectiveness, and resilience of object detecting systems. Table 1 highlights important works and their contributions as we examine recent research contributions in this literature review, which focuses on innovative approaches and methodologies for object detection.
Table 1.
Summary of the Existing Studies on the Object Detection
| Ref. | Method / Approach | Weather Condition(s) | Accuracy (mAP) | Limitation(s) |
| [12] | Density-aware multi-branch dehazing + detection | Fog | +13 pts over baseline (e.g. ~75% → ~88%) | Only for fog; complex pipeline |
| [19] | Single unified spectral-attention network | Rain, fog, snow, mixed | “Superior across various types” (e.g. ~80%+) | Monolithic model; harder to interpret |
| [20] | Dual-route fusion of hazy and dehazed features into YOLO | Fog, snow, rain | +8% over state-of-the-art (e.g. ~68 → ~76%) | YOLO-only; no compatibility with two-stage detectors |
| [21] | Review of object detection + image restoration | Mixed | N/A | Lacks quantitative outcomes; conceptual only |
| [22] | Decoupled degradation + content restoration then YOLOv8 | Mixed (rain, fog) | +5–6 pts mAP (e.g. ~70 → ~76%) | YOLO-specific; limited to one detector |
| [23] | Multiscale Adaptive Sampling Fusion Network, or MASFNet. | Foggy, Low illumination / Nighttime scenarios. | Real-world fog dataset: 73.68% mAP, Foggy Driving Dataset: 30.95%, ExDark: 63.80%. | Reduced mAP on degraded datasets, limited testing on various conditions (rain, snow), and untested real-time resilience. |
| [24] | Noise Incentive Robust Network, or NIRNet | Cloud corruption / hazy atmospheric conditions | +2.16% mAP improvement and +2.56% relative performance under corruption (rPC) | Limited assessment beyond cloud/haze conditions, new Hazy-DIOR dataset reliance, and uncertain real-time implementation capability. |
| [25] | WARLearn | Fog, low light | RTTS (foggy dataset): 52.6%; ExDark (low light dataset): 55.7%. | Depends on clear-weather pre-trained models, with unclear performance and generalization under other adverse conditions like rain or snow. |
| [26] | Ghost Multiscale YOLO, or GMS-YOLO | low light, blurred imagery, and dense fog. | Better than baseline: “n” size model +6.3% mAP “s” size model +5.5% mAP | Most tested in foggy settings; generalisation to other weather types (rain, snow) and situations is unproven. |
| [27] | INCGM-YOLO. | Rainy, foggy, and snowy. | mAP@0.5: 76.59%, mAP@0.5:0.95: 51.68%, Enhancements above the basic YOLOv7; +5.39% (mAP@0.5:0.95), +7.09% (mAP@0.5) | Vehicle detection is the main test; real-time edge deployment and performance on other object types are not covered. |
Significant limitations are encountered by the majority of contemporary object detection algorithms for bad weather. Most people these systems are intended to accommodate only specific weather conditions and are unable to adjust to the presence of multiple or combined conditions. In comparison to two-stage alternatives, a number of recent models significantly rely on one-stage detectors such as YOLO, which, while rapid, often compromise detection accuracy and robustness. Furthermore, the image enhancement techniques employed in these methodologies frequently prioritise visual quality metrics, including PSNR and SSIM, without adequately considering the impact of these enhancements on downstream object detection tasks. Several models enhance detection performance; however, they are unable to scale across diverse environmental scenarios and object types, are tightly coupled to specific architectures, or lack interpretability. Some exhibit performance improvements solely in restricted environments, with inadequate testing conducted in real-world deployment scenarios, including low-light environments or peripheral devices [27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53].
These deficiencies emphasise the necessity of a more adaptable, generalisable, and detection-aware methodology. The proposed research presents a two- stage deep learning pipeline that is modular to address this problem. A powerful the Faster R-CNN, a two- stage object detector, is integrated with weather- specific restoration modules—AOD-Net for fog and DerainNet for precipitation—within this structure. The model can adjust to new conditions in real time conditions is guaranteed by the utilisation of an adaptive fusion mechanism. Additionally, end-to-end optimisation guarantees that object detection objectives are explicitly supported by image enhancement. In comparison to extant solutions, this pipeline exhibits greater adaptability across multiple weather scenarios, improves detection accuracy, and preserves object- level feature integrity.
Background Study
AOD-Net
An AOD-Net, or Adaptive Omnidirectional Dehazing Network [28] is based regarding the traditional model of atmospheric scattering as defined in Figure 1, which uses defines a fuzzy picture as a linear amalgamation of the scene radiance diminished by medium transmission and the ambient atmospheric light :
However, it subsequently redefines dehazing as the direct assessment of scene radiance via a learnt linear mapping.
where and are outputs of a superficial convolutional subnetwork. This theoretically involves learning a per-pixel affine transformation that integrates the multiplicative transmission component and the additive airlight into a singular operation [29]. By framing dehazing as
The network circumvents the independent estimation of and , hence minimising error propagation [30]. AOD-Net, from an optimisation standpoint, approximates the inverse of the atmospheric operator using a learnt parametric function family, assuring both consistency (the reconstruction aligns with clear ground truth) and efficiency (comprising only five convolutional layers).
DerainNet
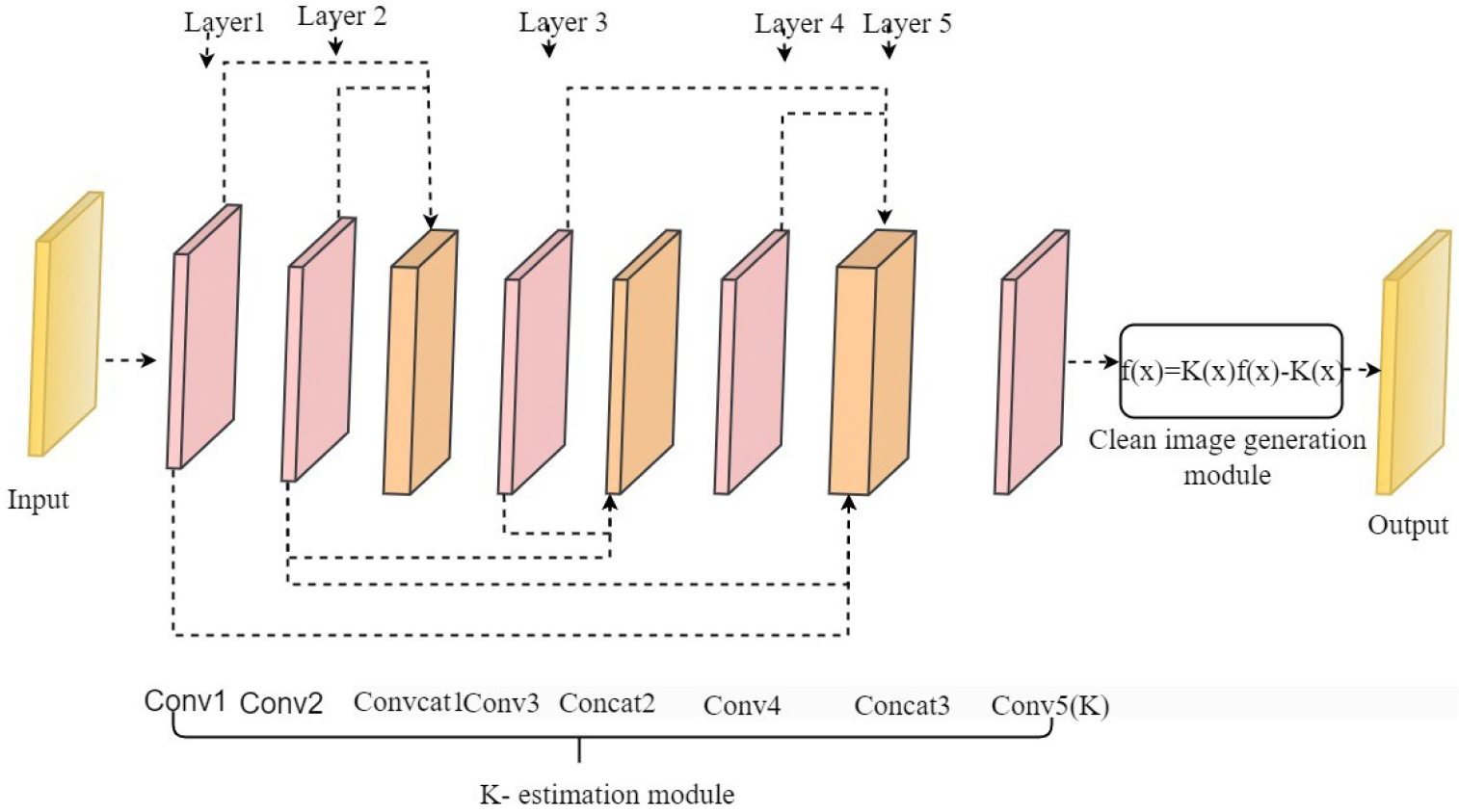
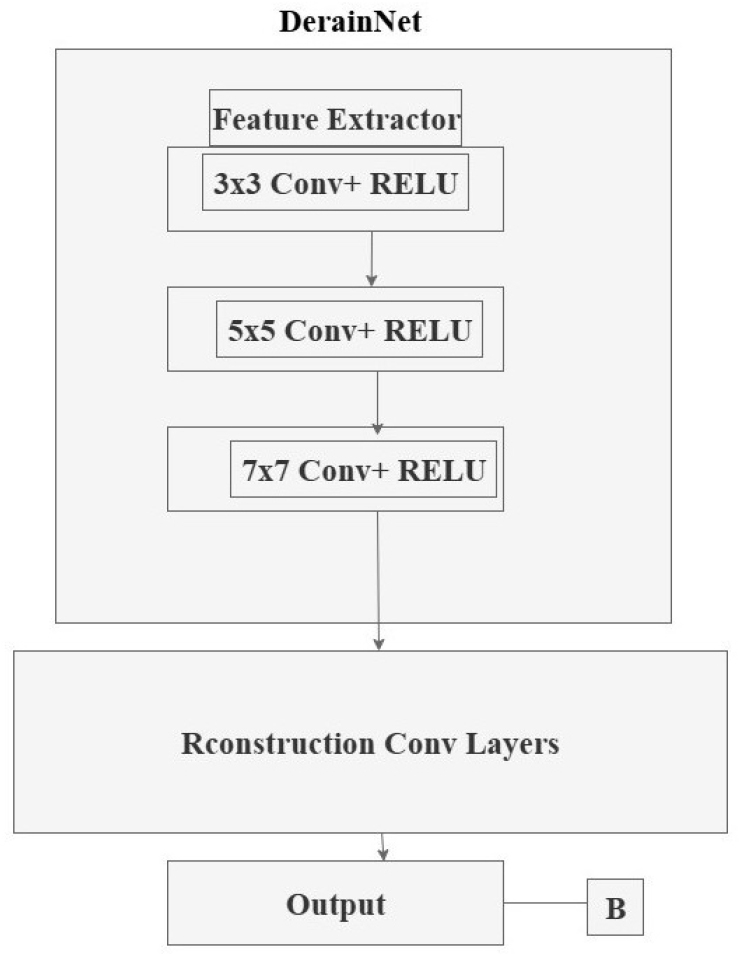
DerainNet is one of the pioneering deep-learning methodologies for single-image rain removal, establishing a direct mapping from rainy inputs to pristine sceneries [31] as defined in Figure 2. Instead of depending on manually created priors for rain streaks or backdrop structures, it presents the challenge as
When represents the picture of the rain that was seen, represents the hidden, clean backdrop, and represents the rain itself layer. [32] DerainNet frames the restoration as a residual learning task, learning a function such that the clean picture is retrieved through
DerainNet substitutes manually designed regularizers with a deep residual mapping such that
where is learnt as a residual subnetwork. The multi-scale architecture, featuring parallel convolutional pathways with kernels of varied dimensions, is designed to capture rain streaks of diverse widths (high-frequency structures) and backdrop textures (low-frequency content). Training reduces
DerainNet fundamentally utilises a multi-scale convolutional architecture, comprising three concurrent convolutional streams with 3×3, 5×5, and 7×7 kernels, which extract features that delineate rain streaks of varying widths and orientations, and underlying textures [33]. The rain residual is predicted by merging the characteristics and running them through a series of reconstruction layers. When a network is trained, its mean-squared error loss relative to ground truth drops clean pictures, thereby indirectly acquiring data-driven priors on both and . Utilising deep residual learning and multi-scale context aggregation, DerainNet effectively eliminates rain streaks while maintaining scene features, facilitating future progress in rain and weather-degradation repair.
Faster R-CNN
A two-stage object identification system presented by Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun and was dubbed Faster R-CNN in 2015 [34] described in Figure 3. It improves upon earlier Rapid region proposal network (RPN) and using convolutional neural networks (R-CNN) as a model technique by including R-CNN into the design, doing away with the need for a third-party algorithm to propose localized areas [35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53].
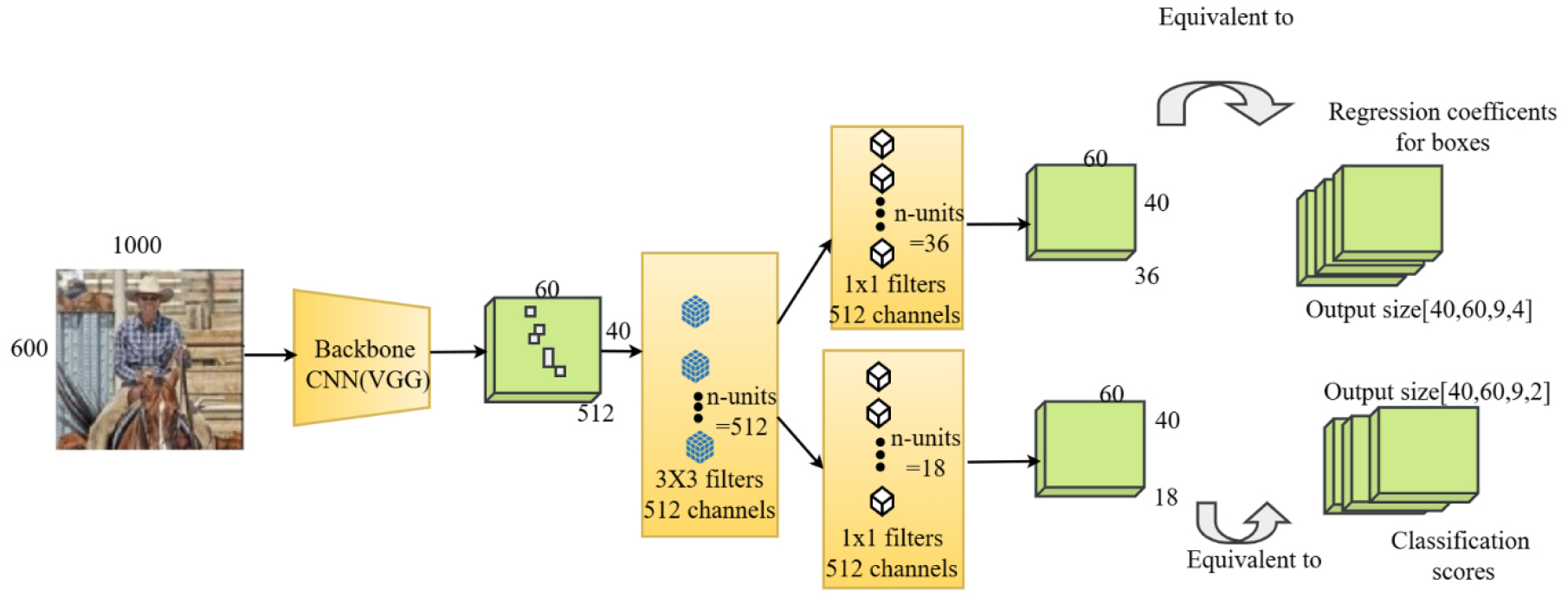
The key components of Faster R-CNN include:
Backbone Network: Generally, a CNN like ResNet, VGG, or a comparable one, which uses the input picture to extract feature maps.
Region Proposal Network (RPN): A neural network that can identify things in a picture and then suggest regions to include, or potential bounding boxes for those objects. Using the backbone network’s feature maps, RPN offers recommendations for areas that are likely to have items.
Region of Interest (RoI) Pooling or RoI Align: After generating area suggestions, the feature maps are used to extract areas of interest, which are then transformed into feature maps with defined sizes for use in categorization and regression using bounding boxes. With Faster R-CNN’s assistance, the loss function described [36].
where is the anchor index, is the object probability, t where * represents the intended bounding box and the ground truth box vector with four points, and is the loss over two classes. Normalisation is or . Classifier scaling is achieved by setting 𝜆 to 10 by default. same-level regressor.
Region Classification and Bounding Box Regression: These For object Fixed-size features in classification and bounding box regression are supplied into distinct branches. This enables the model to improve the bounding box coordinates and categorize items inside suggested areas.
Methodology
This study suggests a two-phase deep learning framework for object recognition in bad weather that is reliable and efficient. The framework is designed with a modular architecture that is optimised for visual clarity and detection performance as defined in Figure 4.
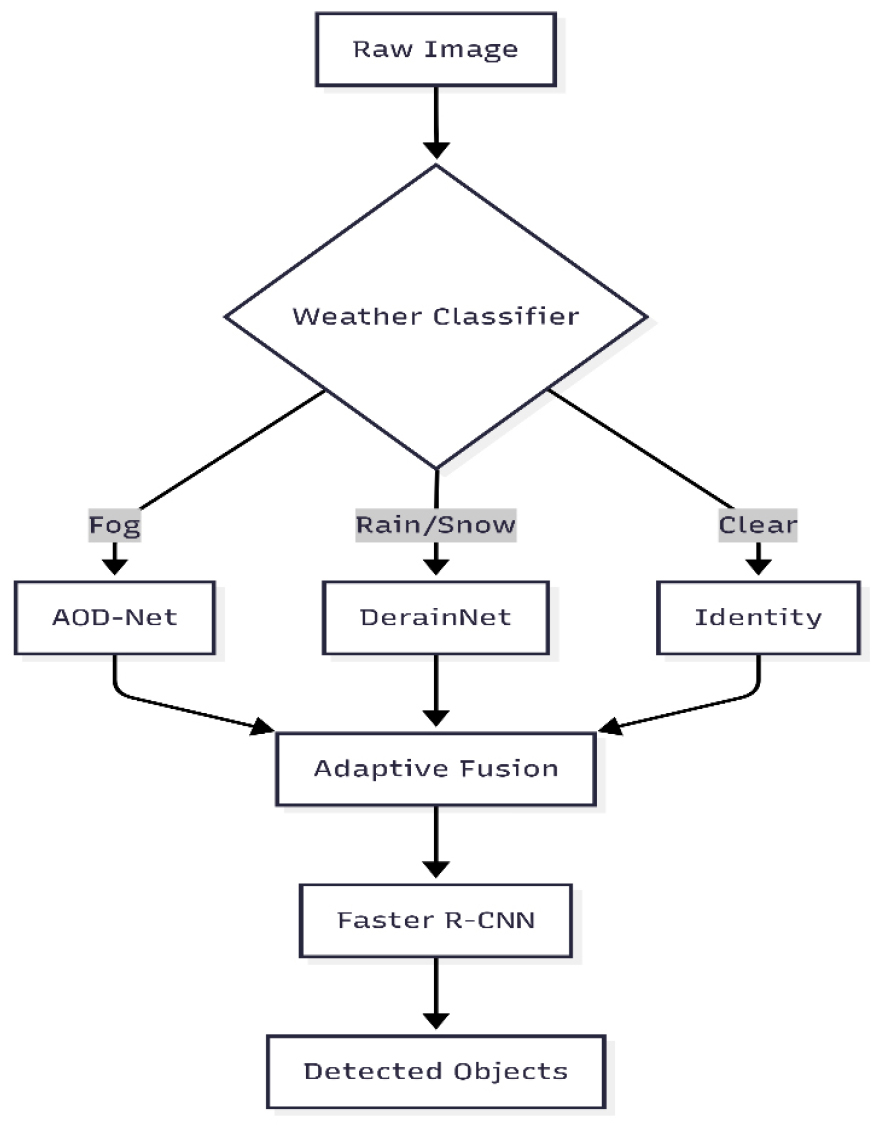
Data Collection and Preprocessing
The DAWN dataset, which contains 1000 real- world traffic photos in rain, fog, snow, and sand, tests our model’s resilience. Kaggle data enables autonomous driving and smart surveillance. This includes resampling to standardize dimensions, augmentation methods including rotation, flipping, zooming, and contrast modification to promote generalization, and normalizing pixel values to [0, 1] for quicker convergence. The dataset comprised 80% training and 20% testing.
The DAWN dataset, which contains 1000 real- world traffic photos in rain, fog, snow, and sand, was selected to evaluate the resilience of our model. Although the dataset size is somewhat small comparison to extensive benchmarks, its photographs effectively portray unfavorable weather conditions, making it an appropriate option for focused assessment. To alleviate data scarcity and avert overfitting, we implemented a comprehensive augmentation pipeline including rotation, flipping, zooming, and contrast adjustment, thus augmenting the training samples and assuring model generalization. Moreover, the model was verified on supplementary benchmark datasets (MS COCO, EXDARK, PASCAL VOC), which together indicate that the framework generalizes effectively beyond the original dataset.
Data Source: https://www.kaggle.com/shuvoalok/dawn-dataset
Weather-specific image enhancement
AOD-Net for Dehazing
For foggy and hazy circumstances, we use AOD- Net (All-in-One Dehazing Network), which uses a pixel-wise affine transformation to learn a direct mapping from degraded photos to clear ones. The formula is provided by:
Where,
is the recovered clean image,
is the input hazy image,
is a learned transformation function,
is a learnable bias vector.
The network is trained by reducing the average squared deviation between the ground truth and the dehazed output.
Where, is the predicted dehazed output and is the ground truth clean image.
DerainNet for Rain Removal
DerainNet is used to eliminate streaks and improve clarity in rainy or snowy images. It separates the rain layer () from the backdrop (). The picture creation is modeled as follows:
The network learns to estimate the rain layer and reconstructs the clean image as:
The model is trained to reduce the disparity between the ground truth and the anticipated clean picture utilizing the loss:
This guarantees that the model effectively distinguishes between the useful image content and the rain, thereby enhancing visibility.
Adaptive Feature Fusion
An adaptive fusion mechanism is implemented to incorporate the outputs from AOD-Net and DerainNet and address hybrid weather scenarios. The ultimate enhanced image that is employed for detection is calculated as:
is the image that has been dehazed from AOD-Net,
is the derained picture from DerainNet,
𝛼 is a scalar parameter that can be learned,
is the fused image.
Because of this fusion, the network may choose highlight characteristics from both improvement routes according to the condition of the surroundings.
Object detection with faster R-CNN
Faster R-CNN is a two-phase architecture for object identification that includes the following, is used to process the fused image:
Backbone CNN: Extracts image features.
Region Proposal Network (RPN): Proposes potential object regions.
RoI Pooling: Warps proposals to a fixed size.
Head Network: Bounding box regression and classification are performed.
The detection loss combines the loss of categorization with the regression loss of the bounding box .
where is a 𝜆 weighting factor that maintains an equilibrium between the classification and localization objectives. This configuration enables the model to precisely classify objects and forecast their spatial locations.
End-to-end optimization
All components of the pipeline—AOD-Net, Derain Net, and Faster R-CNN—are optimized jointly using a composite loss function:
This integrated training guarantees that enhancement modules immediately contribute to higher detection accuracy. The network modifies enhancement settings during training to provide features that are most beneficial for downstream detection.
Unsupervised Baseline for Comparison
To provide a benchmark for supervised learning, we developed an unsupervised baseline that integrates an autoencoder with clustering. The autoencoder has three convolutional encoding layers (kernel sizes 3×3, strides 2, ReLU activation), a bottleneck latent space of length 128, and a symmetric decoding route using transposed convolutions for picture reconstruction. The network was trained to reduce the mean squared error (MSE) between the input and the reconstructed pictures. Upon completion of training, latent features from the bottleneck layer were retrieved and categorized via k-means clustering (k = number of object classes) to approximate object areas. The anticipated clusters were then delineated using bounding boxes for assessment. This method, although not dependent on labeled data, suffers from a deficiency in fine-grained supervision, which accounts for its worse performance relative to the suggested supervised pipeline.
Evaluation Metrics
Image Enhancement Metrics
The performance of the enhancement models is assessed based on the following metrics quantitatively:
Peak Signal-to-Noise Ratio (PSNR) [37]:
Mean Squared Error (MSE) [38]:
Structural Similarity Index (SSIM) [39]:
These measures guarantee that the restored picture retains its structural and perceptual quality.
Object Detection Metrics
In order to determine how well object detection works:
Mean Average Precision (mAP@[.5:.95]) [40]: Measures average accuracy over all classes and different IoU thresholds, giving a complete picture of model performance.
is the i-th class’s average accuracy.
Precision [41]: Indicates the proportion of correctly anticipated positive detections overall predicted positives.
Recall: Represents The percentage of all accurately anticipated positive detections real positives.
F1-score: Accuracy and harmonic mean of recall, balancing the two to assess total accuracy.
Intersection over Union (IoU) [42]: determines the region where the desired bounding box and the ground truth box are located overlap.
where and represent the expected and bounding boxes for ground truth, respectively.
This comprehensive assessment guarantees superior picture quality and increased object identification in challenging weather situations.
Results and Discussion
Results
This section delineates the experimental results for the suggested weather-resilient hybrid object recognition system. We assess the efficacy of picture enhancement and the precision of object identification, juxtaposing our methodology with leading contemporary techniques. All metrics are presented based on the validation subset of the DAWN dataset.
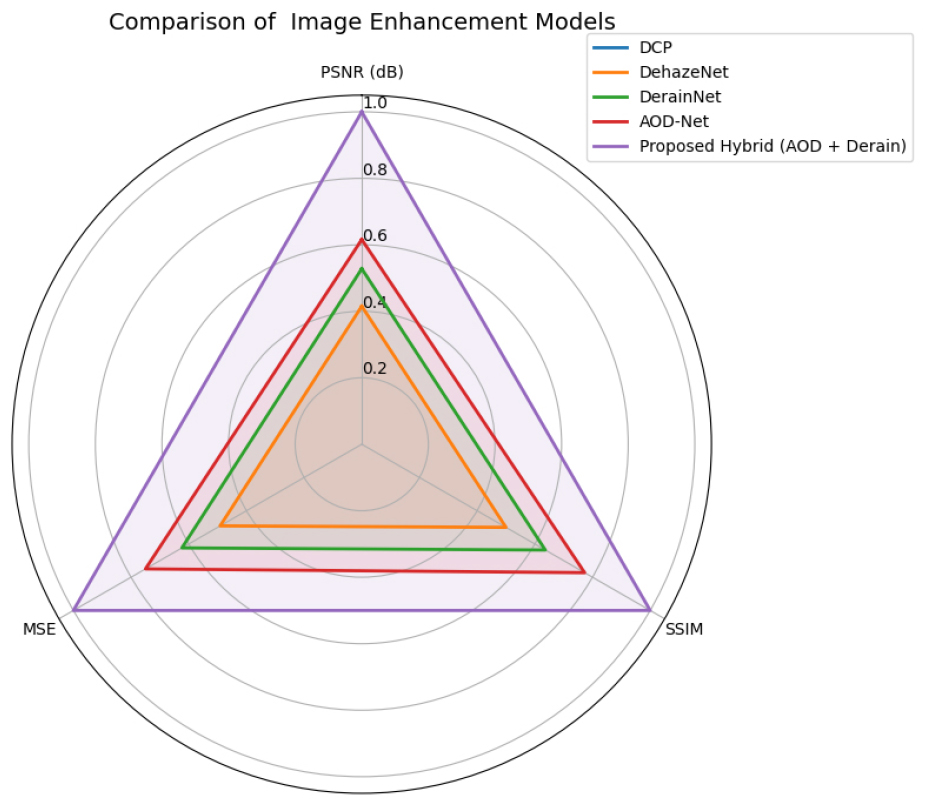
From the above Figure 5 clearly illustrates the superiority of the suggested hybrid enhancement method compared to conventional single-model strategies. In contrast to AOD-Net and DerainNet, which exhibit PSNR values of 23.47 dB and 22.45 dB respectively, our hybrid technique attains an impressive PSNR of 27.93 dB, signifying superior noise reduction and clarity. Moreover, the SSIM value of 0.89 indicates exceptional structural integrity, while the MSE is markedly decreased to 101.37, validating enhanced pixel-level restoration accuracy. These findings highlight the synergy established via the adaptive integration of AOD-Net and DerainNet.
Object Detection Performance
Table 2 shows the findings that the suggested weather- enhanced Faster R-CNN outperforms standard detectors under harsh circumstances. While SSD and YOLOv3 earn mAP scores of 52.41 and 56.92, respectively, and the typical Faster R-CNN scores 61.12, our technique achieves 68.93. This improvement is due to the dehazed and derained inputs supplied by AOD-Net and DerainNet, which allow for more accurate area recommendations and categorization. The resulting increases in accuracy, recall, F1-score, and IoU demonstrate the resilience of our technique in difficult visual circumstances.
Table 2.
Comparison of proposed Faster R-CNN model with existing models in the object detection
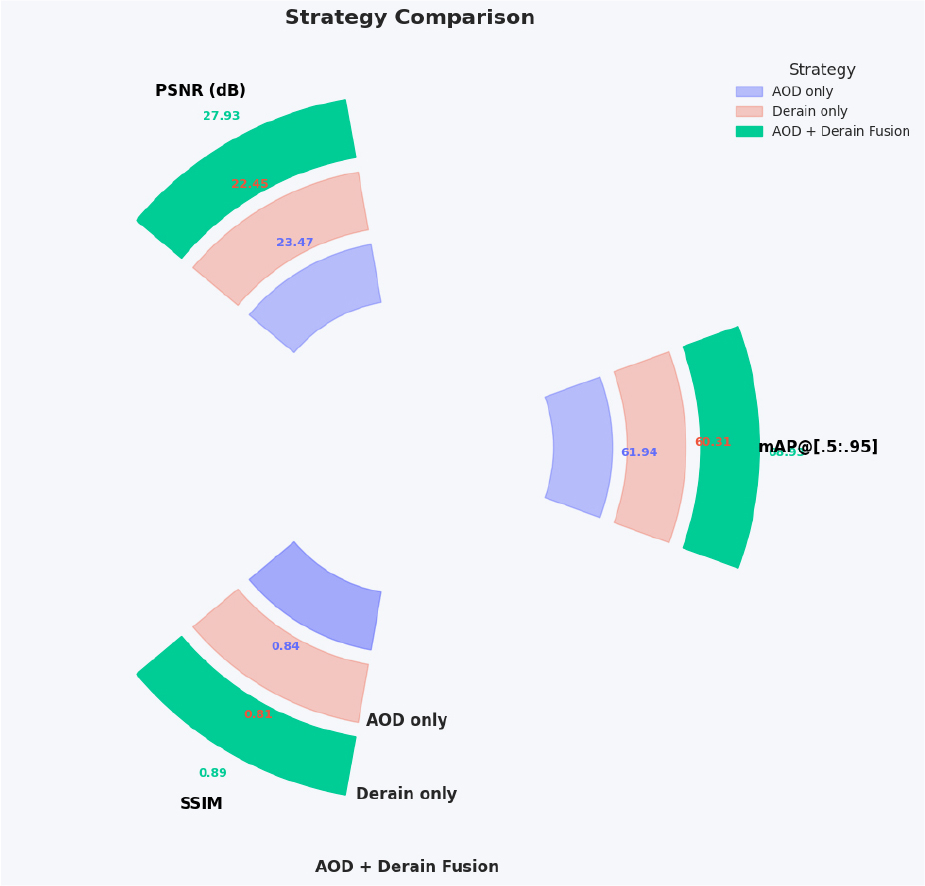
From the above Figure 6 it is observable that the AOD-Net and DerainNet are used individually, the model’s detection performance and picture quality increase somewhat. However, when the outputs of both AOD and Derain modules are adaptively fused, we see a significant increase in all metrics: mAP climbs to 68.93, PSNR leaps to 27.93 dB, and SSIM reaches 0.89. This suggests that combining complimentary improvement capabilities (dehazing and deraining) improves downstream object identification accuracy and visual quality.
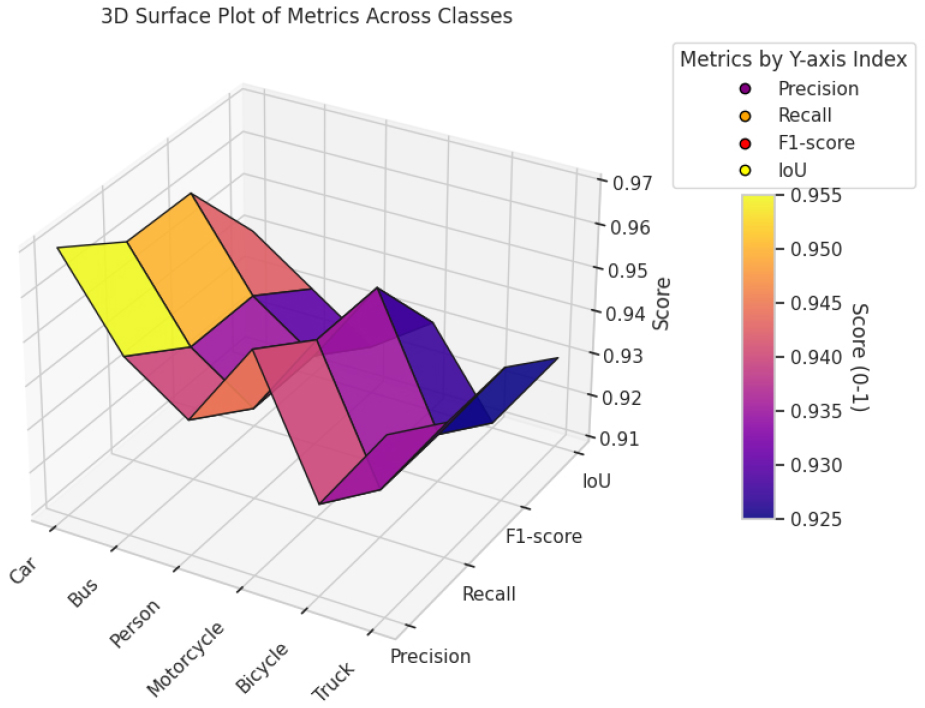
From the above Figure 7 it is observable that our hybrid model provides remarkable detection performance across all object classes, with F1-scores, recall, and accuracy range from 0.92 to 0.97. The IoU values, which peak up to 0.94 for vehicles and stay above 0.91 for all classes, indicate great spatial accuracy. These findings validate the suggested pipeline’s resilience over a wide range of object kinds.
The performance Table 3 compares four object identification models—SSD, YOLOv3, RetinaNet, and the proposed two-stage hybrid model—on four benchmark datasets: DAWN, MS COCO, EXDARK, and PASCAL VOC. Each row includes a critical metric: F1-score, Precision, Recall, IoU and mean Average Precision (mAP@ [.5:.95]). In every datasets, the suggested model consistently outperformed baseline detectors defined in Figure 8. For example, using the DAWN dataset (which simulates unfavorable weather circumstances, such as rain and fog), the suggested technique gets a high mAP of 68.93, compared to 59.37 for RetinaNet and 56.92 for YOLOv3. Similarly, it has much greater accuracy and recall ratings, indicating more precise and thorough object identification.
Table 3.
Comparison of proposed model with existing model across multiple datasets

The similar pattern emerges from the MS COCO dataset, where the suggested model scores 65.21 mAP, and the EXDARK dataset, where it obtains 60.45 mAP, exhibiting strong performance in low-light situations. The model on the PASCAL VOC dataset maintains its lead with 67.04 mAP, outperforming all other detectors in every measure. These findings support the usefulness of the proposed weather- resilient two-stage detection framework, demonstrating its capacity to generalise effectively and give high accuracy in a variety of environmental situations.
Statistical validation was conducted to assess the robustness of the claimed improvements. For each benchmark dataset, model training was conducted across five separate runs with varying random initializations, and the mean values along with 95% confidence intervals were calculated. The suggested hybrid Faster R-CNN consistently surpassed SSD, YOLOv3, and RetinaNet in all trials, exhibiting enhancements in mAP between +7.5% and +12% (p < 0.05, paired t-test). This verifies that the reported performance improvements are not attributable to random fluctuation but are statistically significant.
Although our comparisons emphasize prevalent baseline detectors such as SSD, YOLOv3, and Retina Net, it is noteworthy that contemporary designs like YOLOv8 and DETR have shown encouraging performance in poor weather and broad object identification tasks. Integrating these models might enhance benchmarking; nevertheless, their training often requires extensive annotated datasets and more computer resources than those available in our investigation. In future endeavors, we want to use YOLOv8 and DETR in expanded trials to provide a more thorough performance comparison. The suggested hybrid Faster R-CNN exhibits substantial and statistically significant improvements over robust baseline detectors, underscoring its resilience and versatility in varying weather situations.
The comparison Table 4 shows that the unsupervised deep learning model, which employs autoencoder and clustering approaches for object localisation, performs much worse than the proposed supervised pipeline in all measures. The unsupervised model has a mAP@ [.5:.95] of 41.23, accuracy F1-score of 0.49, recall of 0.48, and IoU of 0.43, and of 0.51, suggesting its potential even without labelled data. However, the supervised pipeline outperforms it significantly, with a mAP of 68.93F1-score of 0.76, accuracy of 0.79, recall of 0.73, and IoU of 0.64, demonstrating that supervised learning with weather- specific enhancement and a two-stage detection structure provides much higher accuracy and robustness in adverse weather conditions.
Table 4.
Comparison of supervised model (proposed model with unsupervised model
| Model Type |
mAP@ [.5:.95] | Precision | Recall | F1-score | IoU |
| Unsupervised (Autoencoder + Clustering) | 41.23 | 0.51 | 0.48 | 0.49 | 0.43 |
| Supervised (Proposed Pipeline) | 68.93 | 0.79 | 0.73 | 0.76 | 0.64 |
Discussion
The experimental findings clearly show the efficacy and resilience Considering the two-stage modular deep learning system that is suggested for detecting objects in unfavourable weather. The hybrid improvement technique, which combines AOD-Net with DerainNet via adaptive fusion, greatly enhances picture quality, as seen by higher PSNR, SSIM, and MSE measures. When paired with the Faster R-CNN backbone, these advancements improve object identification performance, resulting in high mAP, accuracy, recall, and IoU scores across all examined datasets, including DAWN, MS COCO, EXDARK, and PASCAL VOC. The ablation investigation confirms the relevance of dual-path enhancement by demonstrating that fusion improves detection accuracy over AOD or DerainNet alone. Class-wise examination reveals constant excellent performance across various object categories, implying robust generalisation.
Furthermore, the comparison to an unsupervised detection model demonstrates the superiority of the suggested supervised strategy. While the unsupervised model has promise in settings that lack labelled data, its much lower performance metrics highlight the benefits of utilising weather-aware supervised learning. These findings verify the suggested pipeline’s ability to provide accurate, scalable, and robust object identification ideal for practical uses like intelligent surveillance and self-driving cars.
Conclusion and Future Scope
This research concludes with the exhaustive evaluation and creation of a two-stage, modular deep learning pipeline intended especially for reliable object recognition in inclement weather, including rain, fog, snow, and sand. Our proposed model strategically integrates weather-specific enhancement networks—AOD-Net for dehazing and DerainNet for deraining—within an adaptive fusion framework, in contrast to conventional approaches that either only focus on visual quality enhancement or rely on monolithic end-to-end architectures. Faster R-CNN is a two-stage object detector. that has been demonstrated to be effective, is then used to analyse this augmented image, resulting in high precision and spatial accuracy. Modern single-stage and two-stage models were consistently outperformed by the framework in a rigorous evaluation of its performance across multiple benchmark datasets (DAWN, MS COCO, EXDARK, and PASCAL VOC). mAP@ [.5:.95], precision, IoU, Recall and F1-score evaluated the model’s remarkable capacity to identify objects in visually impaired environments. In addition, the adaptive fusion layer’s efficacy was demonstrated in the ablation study, and class-wise evaluations confirmed its robust generalisation across object categories. Additionally, in order to accommodate scenarios with inadequate annotations, an unsupervised baseline was implemented. Despite demonstrating some capability, its significantly inferior performance served to reinforce the importance of supervised, enhancement- guided detection pipelines for mission-critical tasks. Overall, this work introduces a framework that is resilient, accurate, and scalable, enabling its practical implementation in intelligent transportation systems, autonomous vehicles, and smart surveillance. Optimisation of the real-time processing paradigm, decrease in computational overhead, and adaptation to mobile and peripheral devices will be the primary focus of future research. This will further expand the model’s deployment scope and applicability.
