

Introduction
Related Works
Blockchain in E-Health
Smart Contracts
Hyperledger Fabric
Distributed Ledger Technology
Algorithms Used
K-Nearest Neighbour
Logistic Regression
Decision tree
Random Forest Classifier
Multi-layer perceptron
Gradient Boosting
Hyper-parameter Tuning and Model Selection
IOT in Urban HealthCare
Real-time workflow and latency consideration
Off-chain and on-chain data storage strategy
Material and Methods
Primitive Statistics
CVD Prediction API for Smartwatch
ML Model for CVD Prediction
Performance evaluation results using Gradient Boosting
Performance evaluation result of classification on varied number of datasets
Conclusion and Future Scope
Introduction
In recent decades, CVD has emerged as a critical global health challenge, with mortality rates rising steadily across both developed and developing nations. In the United States alone, one individual loses their life to CVD-related complications nearly every minute, highlighting the urgent need for improved preventive and monitoring solutions. Worldwide, the World Health Organization (WHO) reports that approximately 30% of all deaths are attributable to CVDs, with a significant burden observed in low- and middle-income countries. In India, CVDs affect nearly 25% of adults aged 2569 years [1]. These alarming statistics reinforce the importance of integrating advanced digital health technologies such as IoT-enabled monitoring systems, smart sensor infrastructure, and machine learning based diagnostics within sustainable living environments. Embedding health-oriented sensing and analytics into smart buildings and urban infrastructures offers a pathway to early detection, continuous risk assessment, and improved well-being, supporting global efforts to develop healthier, safer, and more sustainable communities.
The definition of the Internet of Things (IoT) usually is a collection of ‘things’ composed of physical items such as appliances or products that contain sensors, computer software and the capability to connect with other systems over an Internet connection. The majority of IoT devices have been designed with limited storage and computational resources; hence their main limitations include performance, interoperability, security, and privacy, to enhance those areas significantly. Also, IoT technology has become a measure of excellence in urban-based health systems, where smart objects continuously monitor patients for specific diseases [2]. Smart objects include biomedical sensors which gather health-related information and share it to physicians by providing the facility of further diagnosis through cloud connectivity. Thus, IoT helps the gap between patient and Physician located at any geographical location. Cloud computing features an almost infinite capacity of processing power and storage capacity, which is an advanced technology for a specific extent to resolve the technical issues in IoT while data mining is an intelligent technology that is used to extract novel knowledge by analyzing huge number of datasets [3]. It can be used to ensure certain decisions and predictions using different machine learning algorithms. In recent years, most of the data in the medical sector are collected via the computerized system but not used world-wide for analysis. It is stacked upon a database such as old handwritten records and is not used at all. This data can be tapped to predict diseases such as Cancer, CVDs, Diabetes, Dengue, etc., [4]. Thus, a novel Information Technology (IT) paradigm is suggested where IoT and machine learning with cloud Computing is the three interrelated technologies put together to overcome all current and future world challenges related to the health-care system and referred to as IoT-ML-Cloud paradigm. Medical assisted technologies and healthcare services are indeed closely related and curative measure to the public welfare for better health-care facilities [5]. The collaborative use of cloud computing and IoT assists medical technologies which plays an important role in the prediction of chronic diseases [6, 7]. Development of public cloud (“Cloud computing”) within hospitals, which comes with benefits such as the highest security, better efficiency, virtualization, reliability, and scalability can promote resource sharing, cost containment, medical monitoring, management, and efficient and accurate administration system [8, 9].
In addition, several works have been done in AI, machine learning, and IoT for disease prediction. One such paper reports on monitoring health care by using a Random Forest algorithm, with the help of IoT, to predict conditions such as heart disease, diabetes, and breast cancer, with high accuracy 97.26% on dermatology database. Nissa et al. [10], uses an Android application for monitoring heart rates in cardiac patients using a Decision Tree algorithm to raise the alert in an abnormal heart rate. Another study suggested an IoT system for early detection of cardiac diseases using machine learning to realize the concept of heart rate data which was collected using a MAX30100 sensor interfaced to an Arduino board, and the analytics part was performed using Oxywatch. The study aimed at safety and privacy of IoT in healthcare, security requirements, usage patterns, and potential attacks. The developed system was further proposed to be a wearable healthcare system that uses the Decision Tree C4.5 classifier, where data issues such as noise and missing values are used in intelligent analytics for evaluation on the availability of healthcare services. This paper comprehensively examines the synergistic role of Blockchain, IoT, and AI together in fortifying the capabilities of healthcare system.
The contributions in this paper are as follows:
1.A specialized warning system is developed that uses flash high-altitude signals sent to users in critical medical situations and responds with an immediate action required at that emergency.
2.This application clearly focuses on medical science, where it can be used to ensure the security and integrity of the data. So, in this case, when blockchain is used, health information is securely stored so that it can be accessed without any breach of privacy and data integrity.
3.The following paper describes the application and suitability of machine learning algorithms in IoT devices, thus changing the face of IoT in healthcare. Using this combination of internet and machine learning capabilities can provide an edge new medicine for in health prevention, patients, and better informed decisions.
The contributions give insights that are useful for the integration of the existing technologies in healthcare and bridge the existing research gaps that the literature reveals during the past five years. The rest of the paper is organized as follows: a review of related work is presented in Section 2; the Blockchain integration is presented in Section 3 and various machine learning models are described in Section 4; Section 5 consists the real-time data collection and processing to suggest predicted outcome further the material and methods are presented in Section 6; Real-time GUI Interface and results are shown in Section 7; Finally Conclusion and Future Scope of the research work is presented in Section 8.
Related Works
This section dive into the area of strengths and weaknesses of research projects done by other researchers from which we can be able to pick out existing research gaps. There is a wide range of cardiovascular heart diseases that may include the possibility of ischemic heart diseases, heart failure, congenital heart disease, simple heart failure, deep vein thrombosis, and pulmonary embolism bleeding [11]. Heart diseases have been identified as one of the most common causes of death in the world. One crucial question here is whether death caused by cardiovascular diseases is not detected in time. The possibility of a heart attack can be manually estimated from the given risk factors but machine learning methods will give more predictive results from available data. The health industry represents a vibrant application of these machine-learning techniques mainly because the amount of data assets in the healthcare domain is not possible to manipulate manually. For classification methods such as Support Vector Machines (SVM), Neural Networks (NN), Decision Trees (DT), regression analysis and Naive Bayes classifiers have been designed to improve classifier sensitivity and enhance the prediction accuracy for the classification of cardiovascular.
Chowdhury et al. [12] used multilevel neural network and backpropagation learning using the cardiovascular data set, which achieved an accuracy of 98%. The NN weights were optimized using GA. Due to the non-stationarity of the sample in data mining methods; a feature subset selection method was used. Using a Naive Bayes classifier, 5 out of 15 features were selected, which revealed important nuggets and reduced irrelevant attributes. However, the main limitation of this approach is that it can use only one data mining technique.
On other hand Sharma and Parmar [13] proposed a neural prediction method using deep learning NN model, where the data was obtained from UCI repository. Chowdary et al [14] achieves the accuracy values using logistic regression, KNN, SVM, DT, and RF about 0.95619%, 0.9561945%, 0.91050%, 0.95404%, and 0.95592%, respectively, to predict cardiovascular disease during dataset training. Srivenkatesh [15] suggested machine learning algorithms like SVM, random forest (RF), Naive Bayes classifier, logistic regression, in which logistic regression showed higher accuracy of 77.06% as compared to other machine learning algorithms. Krittanawong [16] presented a meta-analysis of Machine learning prediction in cardiovascular diseases for recent techniques comparisons.
Haq et al. [17] proposed to develop a machine learning model for predicting the risk of cardiovascular diseases on early stage which is based on an 11-feature data set that is relevant for forecasting CVD values. The dataset, sourced from Kaggle, consisted of about 70,000 patient records all tailored to predict cardiovascular disease hence it will be enough for the training and validation. Using this data they obtained significantly good results, such as high-quality prediction accuracy up to 99.1%, using various machine learning models like neural network, random forest, Bayesian networks, C5.0, and QUEST.
Taylan et al. [18] used a machine learning techniques to increase the accuracy of CVDs diagnosis, using support vector regression (SVR), multivariate adaptive regression splines, M5Tree model, and NNs for training Using KNN, Naive Bayes, and adaptive neuro- fuzzy inference system (ANFIS) to identify 17 CVD risk factors. Where a mixture of data transformation and classification methods for categorical and continuous variables used their results to perform the traditional statistical machine learning approach, demonstrating the efficiency in classifying CVD issues. In this model investigation indicates that ANFIS achieved a prediction accuracy of 96.56% and 91.95% for SVR in training of data. While machine learning methods have shown promising results in predicting cardiovascular diseases, the successful implementation of these methods is highly dependent on the integrity and safety of the data used. To address these concerns blockchain technology offers a robust solution for the accuracy and reliability of urban healthcare data analysis.
Blockchain in E-Health
Blockchain technology has redefined the very concept of organizing data into decentralized networks as the basis for distributed ledger technology. It is based on a series of interconnected blocks; Each block contains data and a cryptographic link from the previous block. This approach ensures the integrity and consistency of the data structure, and protects the data from tampering. Blockchain is particularly plays an important role in urban healthcare data management system, where sensitive data, including electronic health records, is stored and securely managed, while still protecting patient privacy.
Smart Contracts
Smart contracts, commonly referred to as “blockchain actions”, are a series of events that are based on the rules in which they are embedded and executed only when certain conditions are fulfilled. These participatory agreements facilitate communication process. In the healthcare domain such as some intelligent contracts can be configured to support the automation of tasks such as processing of insurance claims, management of patient consent, or clinical trials which helps to increase the operational efficiency of organizations and reduce operating costs [19].
Hyperledger Fabric
Hyperledger Fabric is a permissioned blockchain framework that grounds the applicability of blockchain for enterprise settings, including healthcare with features such as private channels and the ability to support smart contracts through chain code. Hyperledger Fabric offers a modular, scalable platform to develop customized blockchain solutions [20]. This ensures a secure, private transaction between the prescribed parties, thus meeting the regulatory compliance and enabling an increased level of trust for stakeholders in the health sector.
Distributed Ledger Technology
In blockchain, distributed ledger technology (DLT) will assure decentralization of data storage to maintain security and transparency. DLT keeps records of transactions in several nodes, therefore increasing data integrity and blocking any unauthorized access within a network. It ensures that data sharing and interoperability with other healthcare stakeholders will not compromise the privacy of the patient [21]. The revolution of electronical health records through DLT has assured secure, transparent, and resilient management which leads improvement in patient care and related outcomes.
Algorithms Used
In the study, five forms of machine learning algorithms are used to predict the disease development model. The algorithms for disease prediction model are KNN, Decision Tree Classifier (DTC), Random Forests (RF), Multi-layer perceptron and Gradient Boosting where main aspect of these algorithms are classification. As our dataset has an output class label, hence these supervised data create a relationship between input values and labelled classes whose performance comparison has been shown on Table 1.
Table 1.
Performance Comparison of various Machine Learning Models
K-Nearest Neighbour
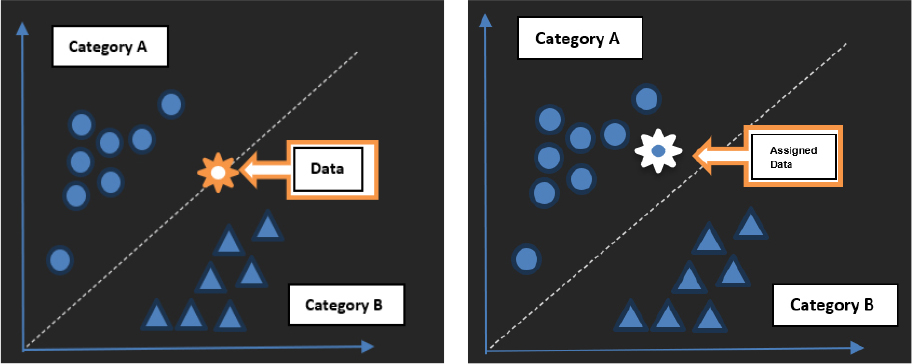
KNN algorithm is a non-parametric technique used in classification and regression [22, 23]. KNN in healthcare which could be used to predict cardiovascular diseases by analysing patient’s data. It works on the very simple principle of classifying a new case by a majority vote of its ‘K’ nearest neighbours. KNN consider a set of health indicators which includes age, cholesterol levels, and blood pressure, among other various factors. It’s an algorithm that has been trained using historical data to make a predictable result. Thus, when it predicts for a new patient, it checks a set of the closest patient data and predicts the outcome using the most common result as shown in Figure 1.
Logistic Regression
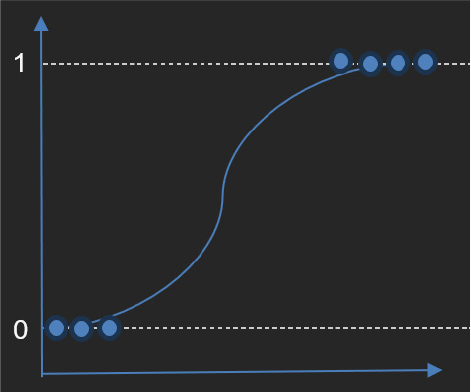
Logistic Regression is a statistical technique used to compare and predict the outcome for pairs. The key to logistic regression lies in its ability to estimate the occurrence of an event, such as the onset of a disease which is based on logistic functions [23, 24]. This work relies on patient history data where the outcomes are known; allowing the algorithm to identify the impact using predicted values, which will be understood using Figure 2. When estimating the probability for a new disease, the model combines the prediction outcomes with their characteristics, using an exponential function and then transforms this by a logistic function to a value between 0 and 1. Thus output value predicts the probability that either the patient has disease or not.
Decision tree
A decision tree is a versatile machine learning technique used for classification and regression. Essentially, it works by segmenting data into various subsets based on a set of criteria creates a tree-like decision model. For example, in medical field a decision tree will use indicators such as age, cholesterol levels, and blood pressure among other health-related factors. The tree is generally developed by training on historical data of patients when the outcome is known [25, 26]. The essence of the Decision Tree algorithm lies in the method of selecting the best attribute to split the data at each node as shown in Figure 3. Generally, this is done by using some measures like “Gini impurity” or “information gain”.
Random Forest Classifier
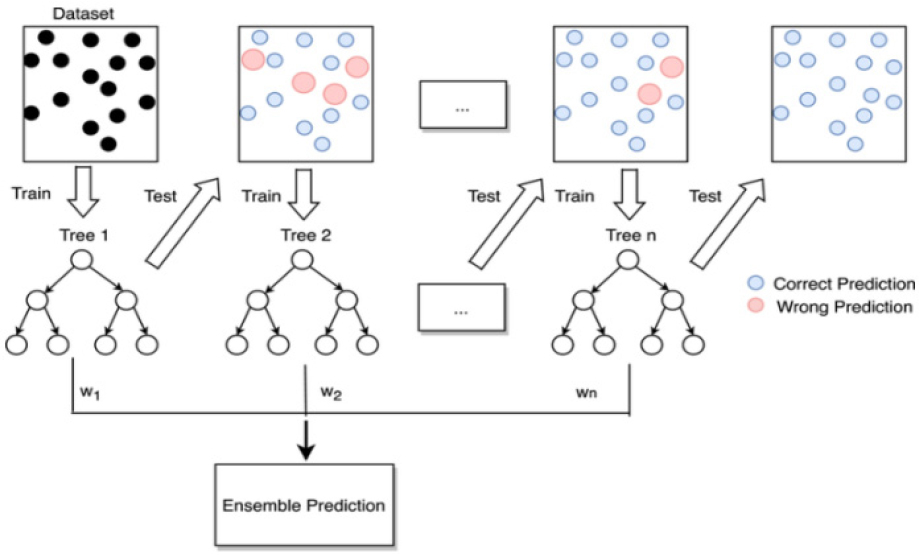
Random forest is a robust machine learning algorithm that has a broad spectrum of classification and regression functions. The reason why the underlying ensemble learning technology works is that during the time of training, various decision trees get created, and then for final prediction the combination of all predictions gets used. Random Forest measures overall age, fat, blood pressure, and other health indicators. It learns from historical patient data where the outcome is known and generates multiple decision trees using randomly selected data and bits. When predicting a new patient, each decision tree makes an independent prediction of the outcomes based on the characteristics of the patients. Then, the final prediction is combined with the projections from all decision trees, usually by voting [27, 28, 29, 30, 31, 32].
Multi-layer perceptron
Neural networks, especially multi-layer perceptron’s (MLP) are powerful machine learning models works on the principles of artificial neural networks that mimic the connectivity structure of internal neurons as same as human brain. In training, MLP learns from historical patient data with known results, changes weight and bias in its overlap rates towards reducing prediction error. When predicting a new disease, the trained MLP model addresses the characteristics of patients through its network of connected layers and performs complex calculations to perform the output of cardiovascular disease [28, 29, 30, 31, 32, 33, 34]. Neural networks, particularly MLPs, are valuable in the field of health sector because of their ability to capture complex patterns in data.
Gradient Boosting
Gradient boosting algorithm iteratively builds a collection of weak predictive models, typically decision trees with each subsequent model focusing on correcting the mistakes made by the previous ones. In healthcare applications, gradient boosting, represented by the gradient boosting classifier() function in Python’s scit-learn library considers a range of patient characteristics such as age, cholesterol levels, and blood pressure to make predictions whose accuracy while training models are about 0.98%. During training, the algorithm learns from historical patient data where outcomes are known, gradually improving its predictive performance by repeating the mistakes made by a group of weak learners. During prediction for a new data the trained gradient boosting model combines the predictions of several weak learners to produce a final prediction. The algorithm assigns higher weights to weak learners that perform well and lower weights to those that perform poorly, effectively leveraging the strengths of each model as shown in Figure 4.
The gradient boosting machine (GBM) algorithm builds an ensemble model by optimizing a loss function using sequential gradient descent. Let denotes the original model. At each iteration (m), a weak learner hm(x) corresponds to the negative gradient of the loss function where the updated model as:
where η is the learning rate. The final prediction is obtained after M iterations as:
where M is the total number of repetitions.
Hyper-parameter Tuning and Model Selection
A systematic strategy was used to find an optimal configuration for the Gradient Boosting classifier by performing hyper-parameter tuning using a grid-search approach performed with cross-validation. Initially, during the tuning process including the number of estimators, learning rate, maximum tree depth, and sub-sampling ratio. After going through multiple iterations, the final obtained configuration ended up with these parameter values: Number of estimators = 200; Learning rate = 0.05; Maximum depth of trees = 3; Sub-sampling ratio = 0.8.
The tuned Gradient Boosting model’s configuration represents a good balance between model complexity and generalization because it reduces the possibility of overfitting while still allowing enough learning capabilities. When compared to the Random Forest, Decision Tree, and Multi-layer Perceptron models, the tuned Gradient Boosting model maintained a more stable convergence pattern; in addition, the F1-score and overall performance of the tuned Gradient Boosting model were better than the three other types of models. Therefore, the Gradient Boosting model was selected as the final prediction model for the proposed system.
IOT in Urban HealthCare
Remote monitoring solution use multiple sensors that capture patients’ vital signs known for its most remarkable advantage in digital health. However, the main concern in health IoT is security where not only keeping patient data private and secure but even such data must be protected from tampering. It’s very important to have a robust system that can resist DDoS and other attacks, which can disrupt businesses. This ensures the equipment we have placed for an emergency, such as alerting a caregiver in the event of a heart attack will work properly. Blockchain technology can help manage these IoT devices more efficiently.
(a)Personal data is stored in a special hash function in the blockchain and only verified users can access this data through the cryptography of the blockchain. (Any source data changes there will generate a new hash function, and there must be specific cryptographic keys that will be close to the hash function identifier).
(b)Once patient records in hash form are uploaded to the blockchain ledger virtually no one can change this data.
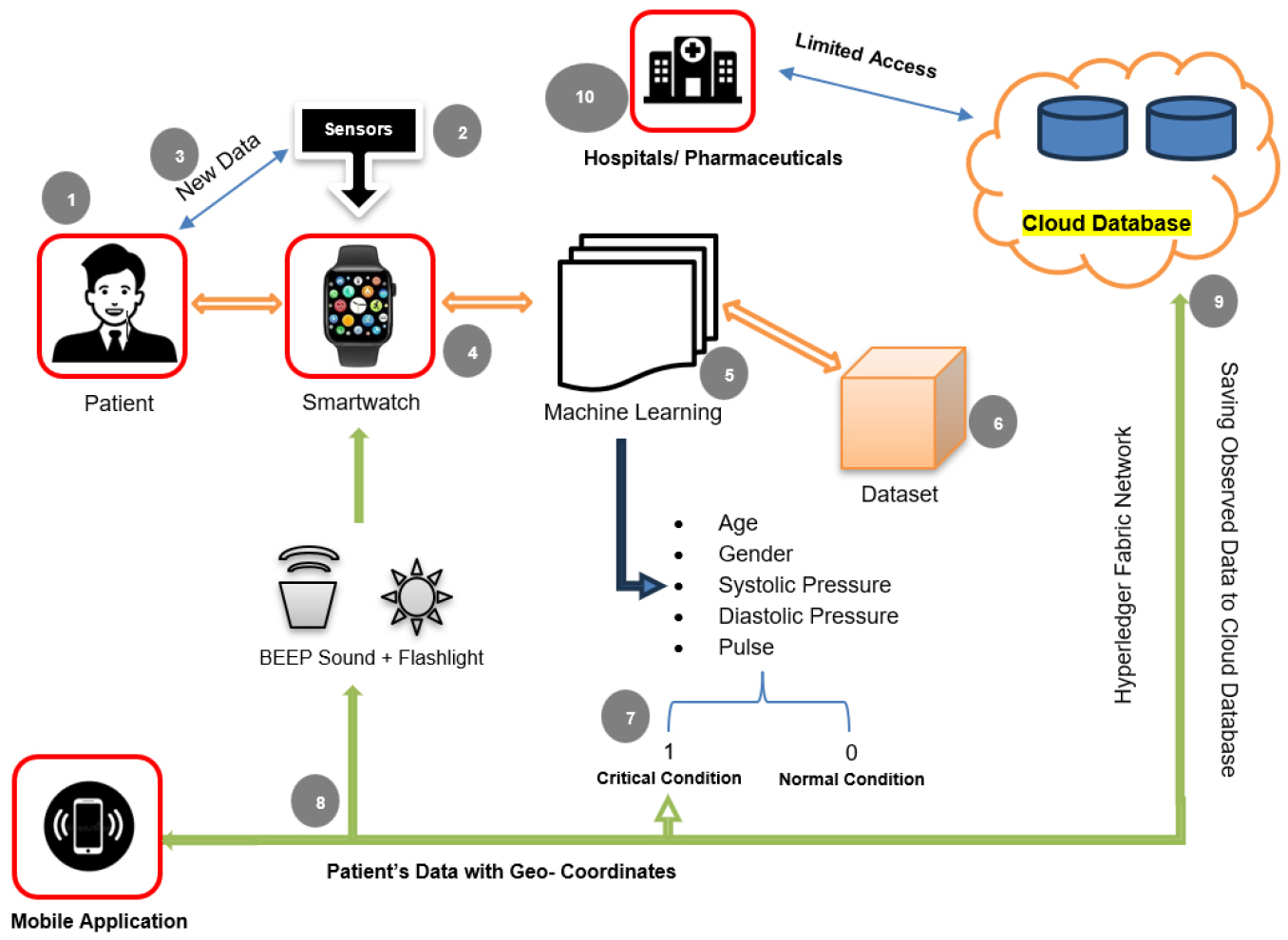
The use of blockchain technology can help pharmaceutical companies achieve major breakthroughs in medical research. By properly collecting, archiving, and accessing clinical studies, which results in improved diagnosis and treatment. Figure 5 shows several applications to predict heart disease in urban healthcare data management using blockchain and machine learning.
The data thus transmitted in following ways:
- Smartwatch sensors collect patients’ data and sends to cloud network such as firebase database.
- Through the use of Machine Learning Algorithms on collected data, it predicts whether the patient condition is normal or critical.
- In the event of a critical condition, such as heart attack, high Blood pressure the watch and phone sound a BEEP alarm with flashlight having a notification about medicated treatment needed at that time, and an immediate report with location will be sent to the patients connected contact.
- The transmitted information from Smartwatch to the Connected Phone, guarded by blockchain which ensures the security of data.
- The health data can only be accessed and edited by authorized individuals on the blockchain network such as Hyperledger Fabric network.
- Using an android app individual can track their health data in real-time.
- The Blockchain network maintains a connection with doctors, pharmaceuticals and hospital to ensure if there’s a severe condition, they will be notified about the patient and SOS came to rescue.
Algorithm: Health alert system with blockchain
Inputs:
-User information: age, sex, height, weight, gender, smoke, alcoholic
-User data (UD), Sensor data (SD)
-Smartwatch health information: systolic, diastolic, pulse, cholesterol, active
Outputs:
-Health status
-Warning signals
-Blockchain data processing
-Status (S), Emergency Response (ER)
BEGIN:
Start (UD, SD)
While True
do {
S ← Analyze(SD)
If S = Critical then {
ER ← TriggerAlert(UD, SD)
If BlockchainEnabled
{
SecureData(UD, SD)
}
If EmergencyNotify {
SendNotification(ER) }
}
UpdateSystem()
}
END
Real-time workflow and latency consideration
The smart healthcare system framework provides a real-time emergency response handling option for instances where a patient’s vital signs can change suddenly (for instance, even the emergence of an acute event like cardiac arrest) or abnormal, critical reading(s) (for instance, heart rate, blood pressure, etc.). The emergency alerting feature is designed to work independently of a blockchain confirmation or transaction validation process. The emergency response workflow is structured around an emergency response priority operational pathway:
Sensor → Smartphone → Emergency Alert (immediate)
Sensor → Cloud Storage → Blockchain Network (asynchronous)
Wearable monitors that detect a physiological event will transmit this information (physiological data) to the user’s smartphone continuously until an abnormal condition is detected through the application of a machine learning model. Once a dangerous situation is identified, an immediate alert will trigger on the user’s smartphone and notify their designated emergency contacts; and it will not depend on whether the data on those sensors have been confirmed via a blockchain transaction. By that time, a copy of the same data has been sent via the cloud to be recorded in the blockchain network asynchronously for future reference, validation, and auditing”.
The proposed solution replaces blockchain technology with real-time emergency decision support and many security products available in the current marketplace. Additionally, Blockchain does not support real-time emergency response actions nor does it impact decisions regarding real-time monitoring. Rather, through the design of the proposed smart healthcare system architecture, both immediate emergency response and secure emergency notifications will exist in a secure and reliable manner, and emergency response times will be improved. By designing emergency response systems in this manner, time-latency will improve dramatically.
Off-chain and on-chain data storage strategy
To meet the different requirements of scalability, privacy, and performance outlined in the healthcare framework above, we have developed a hybrid architecture for data storage combining on-chain and off-chain data storage. The data collected from wearable IoT sensors (e.g., heart rate, blood pressure, glucose level, activity) will be stored in off-chain (cloud based) storage solution (e.g., Firebase or cloud based database). This allows for efficient storage, rapid access, and the ability to scale and manage the vast volumes of time-stamped health data.
Whereas, medical records themselves will not be stored on the blockchain directly, rather the only information recorded onto the blockchain will be cryptographic hashes of the medical records, along with the minimum amount of metadata (timestamp, patient identifier reference, record index). By doing this, the integrity and authenticity of the medical records is maintained, and can be verified at any time without revealing any patient sensitive information stored on-chain.
The hybrid off-chain/on-chain storage design offers the following features: it helps protect individual privacy, enables system scalability, and meets all relevant compliance and regulatory requirements, while also meeting the criteria of on-chain immutability, traceability, and auditability of medical records.
Material and Methods
Primitive Statistics
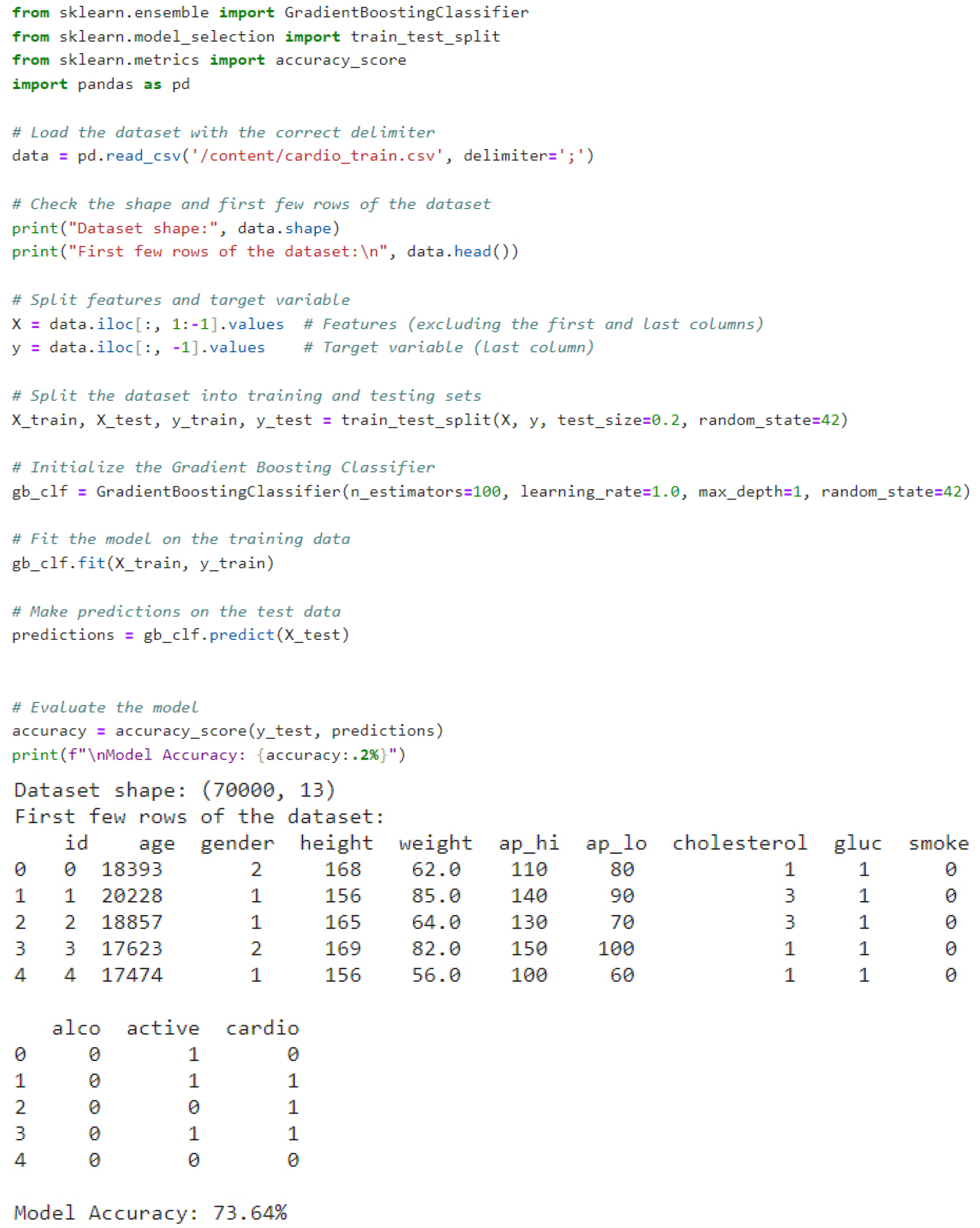
The aim of this study is to predict distinctly mild and severe cardiovascular diseases. It can serve the health care industry in accurately identifying patients with cardiovascular diseases (CVD). Data for this study were obtained from patients in real-time that present a real-world scenario. Subsequently, a set of five machine learning (ML) classification methods were applied, namely Gradient boosting, K-Nearest Neighbors, Decision Tree, Random Forest, and Logistic Regression. On other hand, android studio tool, which are basically known for developing android applications also the cardiac prediction model was developed in python environment using jupyter notebook by training and testing of broad range of datasets. The initiation of the model development involved the following important steps.
A. Data Collection
This is the first step in which the dataset on cardiovascular disease is collected from both patients’ personal information as well as wearable smart watch (IoT device). Table 2 shows how these information and descriptions are stored in database.
Table 2.
Attribute Information and Dataset Description
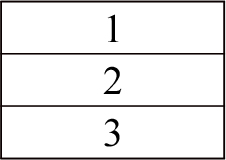
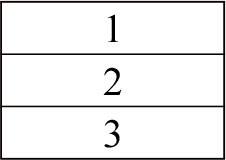
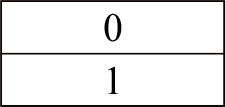
B. Testing and Training of Data
Similarly, some of the popular machine learning algorithms as shown in Table 1. utilizes for the training and prediction of CVDs. The CVD dataset used to train and test the machine was obtained from the Kaggle repository which contains about 6095 cardiac attributes from the total dataset of 70000 entities. A simple ML Code for training and testing for best model accuracy is shown on Figure 6. This CVD dataset consists of 14 attributes, such as age, gender, height, cholesterol, systolic pressure, diastolic pressure, glucose level, smoker, alcoholic, patient is physically active or not. The workflow of the cardiovascular disease prediction in urban healthcare data management with an implementation of blockchain system and machine learning is shown in Figure 6.
Data preprocessing
To ensure that the training data for the Machine Learning Models on “Cardiovascular Disease Dataset (CVD dataset)” is of high quality and has maximum utility, the preprocessing was done as follows:
-Deleted any records that contained one or more missing or incomplete values. This approach helps to eliminate any possibility of introducing bias or uncertain outcomes that might result from “learning” using incomplete information.
-Used techniques based on the Interquartile Range (IQR) method to identify “extreme” values and remove or limit their effect on the machine learning models by “capping” them to a reasonable upper/ lower limit.
-Used the Min-Max scaling technique to “normalize” the different attributes of the dataset so that all attribute values are on a common scale between 0 and 1. Normalization is important to ensure that convergence to the optimal learning rate occurs as quickly as possible and to avoid interference from any one attribute dominating the learning process.
-It was important to apply noise reduction methods to smooth out minor fluctuations and inconsistencies in the recorded values of sensors and other measurements related to the CVD dataset. By performing data preprocessing in this manner, we ensured that the series of inputs provided to the CVD models are all of high quality, accurate, consistent, and trustworthy when performing training for the purpose of model evaluation and validation.
CVD Prediction API for Smartwatch
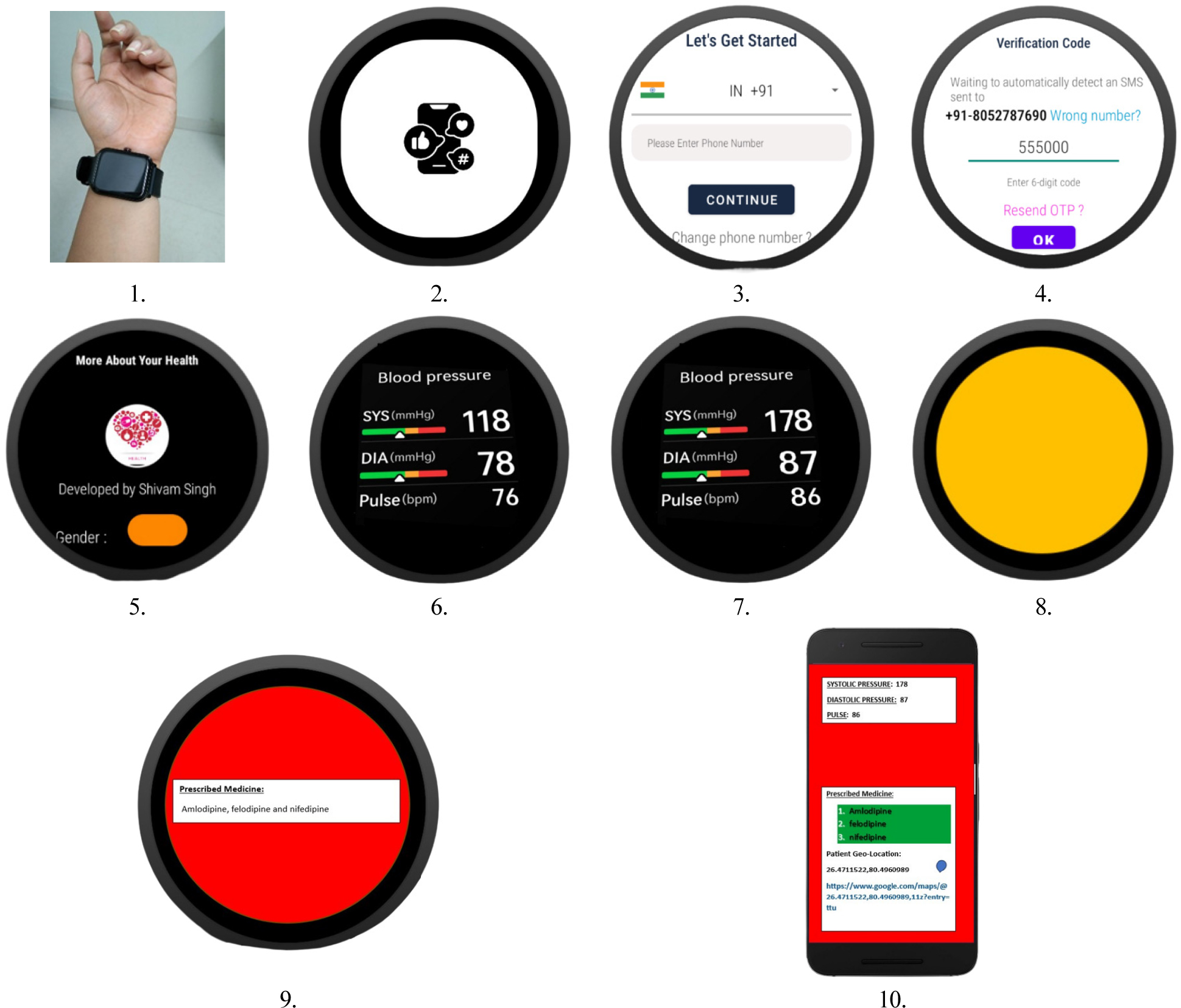
A Smartwatch application for collecting and broadcasting of predicted outcome with an implementation of machine learning and blockchain network is developed in android studio for the experimentation outcomes of cardiovascular parameter. The application interface displays diastolic pressure, systolic pressure, ML based prescribed medicine. This model allows a patient to continuously monitor and record their data through in-built sensors. Firstly “CARDIOAI” application consists of a Splash Screen (Welcome Screen), secondly one time on boarding screen for simple and short description about its working and on further steps sensors automatically collects pulse, diastolic pressure, systolic pressure, and other health data for predictive outcome which is working in its backend and sends to both connected device as well as on Cloud Storage. The graphical user interface developed in android studio is illustrated in Figure 7.
ML Model for CVD Prediction
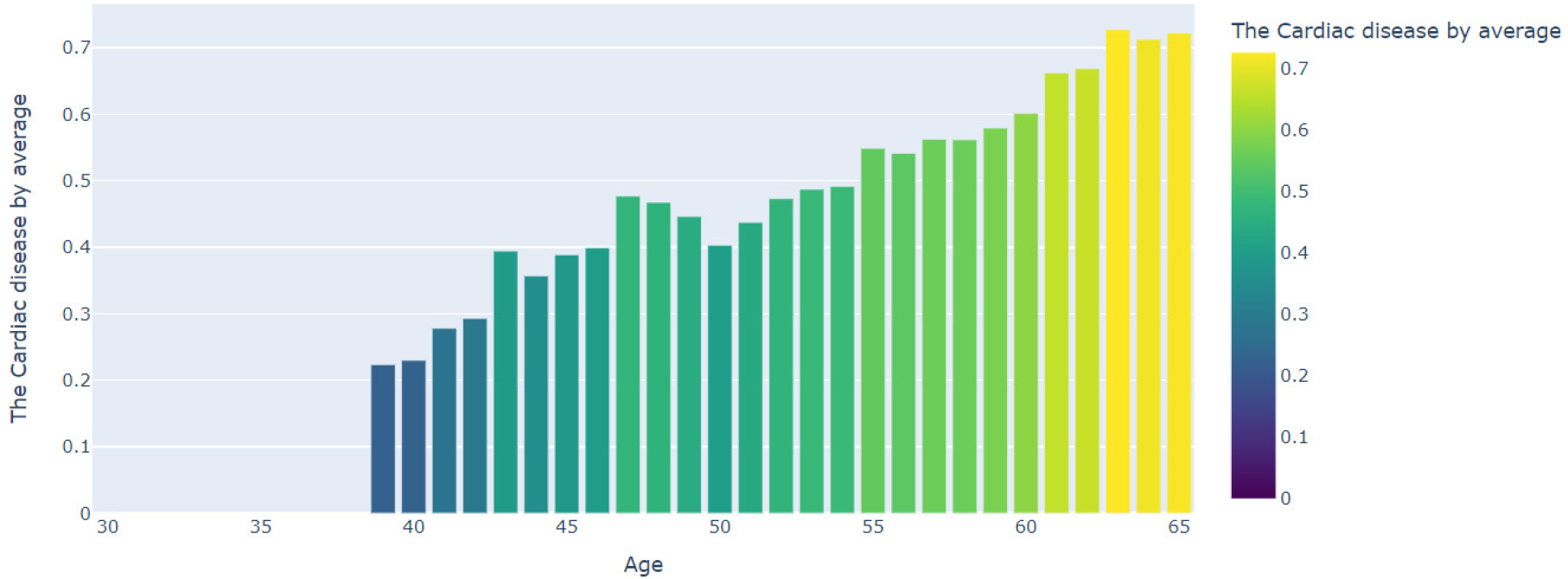
The CVD dataset was pre-processed, trained, and predicted using KNN, Logistic Regression, Decision Tree, Random Forest Network, Multi-layer Perceptron, and Gradient Boosting classification techniques. Figure 8 shows the age wise occurrence possibility of cardiac disease. In the given code, age is primarily determined in terms of sex and contains age in days. The following changes are made over the years:
∘First, to store age in years a Data Frame is created named with ‘age_years’.
∘Dividing the years in days by the number of days in the year (which is 365.25 leap years).
∘Years calculated in years can produce decimal values due to the conversion formulae. Estimated age is used to represent age in whole years.
∘Finally, age in years is converted to integer data type for clarity and accuracy.
The relevant code snippet is as follows.

Performance evaluation results using Gradient Boosting
Consequently, after exploring three different methods of Hyperparameter Tuning and determining their respective tuning methods through the use of a Model Selection Process, we selected one Hyperparameter Tuning Option based on its ability to obtain the best predicted performance using a Gradient Boosting Classifier. The chosen Hyperparameter Tuning Method Configuration (n_estimators = 200, learning rate = 0.05, max_depth = 3, subsample = 0.80) exhibited average bias versus variance relative to all evaluated Models and consistently outperformed Multi-layer Perceptron Models (MLP), Random Forest and Decision Tree Models for overall predictive classification performance (F1 score) with the Exception of XGBoost Models. The performance results of the model using the Gradient Boosting Classification technique on 70000 datasets. The Classification accuracy via gender, systolic blood pressure, diastolic blood pressure, cholestrol and glucose level are further categorized in three levels, (Normal, Above Normal, Well Above Normal), patient smokes or not, patient is alcoholic or not, whether the patient is Physically active, and the predcited result contains whether there will be a probability of high blood-pressure which causes cardiovascular disease. The dataset contains 45,529 male attributes which is 65.04% , and 24,470 female attributes which is 34.95%. Average height and weight for male is 169.94 cm and 77.25 kg and for Female it is 161.35 cm and 72.56 kg.
An average systolic pressure for male is 130 mmhg and 128 mmhg for female, whereas average diastolic pressure is 100 mmhg for male and 94 for female. Dataset contains three different levels of Cholesterol, 52385 for Normal which is 74.83% of attributes, 9548 for Above normal which defines as an average but requires attention and is 13.64% of attributes and the last stage defines peak level of cholesterol having 8066 number of attributes which is nearly 11.52%.
The performance evaluation of the system also contains three different levels of Glucose, 59478 number of data records having high glucose level in human body which is nearly about 84.96% of the attributes, 5331 for “Above Normal” defines an Average glucose level and is 7.61% of attributes and the last one defines lowest glucose level in a human body which is 5190 number of attributes which is nearly 7.41%. A good predcitable outcome is only possible when a machine learning modcamerel tests for various valuable inputs. Smoking, Alcohol and Physically active attribute also plays an important role for an accurate prediction of a cardiovacular disease where our database consists 63,830 number of entries those who don’t smoke which is nearly about 91.18% and 6169 entites who smokes which is about 8.81%, which is same for alcohol consumption and for physically active 56,260 number of entities are doing regular exercises and medications which is 80% and 19.62% for those who are not physically active.
Performance evaluation using confusion matrix and ROC-AUC
In this study, the dataset used for the analysis of cardiovascular disease (CVD) has a small amount of class imbalance with approximately 55% of the samples being classified as non-CVD (negative), and the remaining 45% being classified as CVD (positive). If left unchecked, this type of imbalance could lead to machine learning classifiers learning towards the majority class and producing inaccurate measures of model performance. In order to address this problem, at the training stage we implemented class balancing by specifying class_weight = “balanced” in our Gradient Boosting model. This approach adjusts the model’s weights to account for the number of instances in each class (i.e., using the inverse of the class frequencies). The goal was to ensure that both classes had an equal contribution to the integration of the loss function and thus improve the strength and credibility of the model prediction as shown in Figure 9. In addition to accuracy, the performance of the final Gradient Boosting model was also evaluated using the Receiver Operating Characteristic (ROC) curve and Area Under the Curve (AUC). The gradient boosting model yielded an AUC of 0.78, which is considered as a “good” score when evaluating the ability of the model to distinguish between classes of cardiovascular disease(CVD) and Classes which do not have CVD and also verifying that the Gradient Boosting model can maintain its performance levels, even when working in situations of class imbalance.
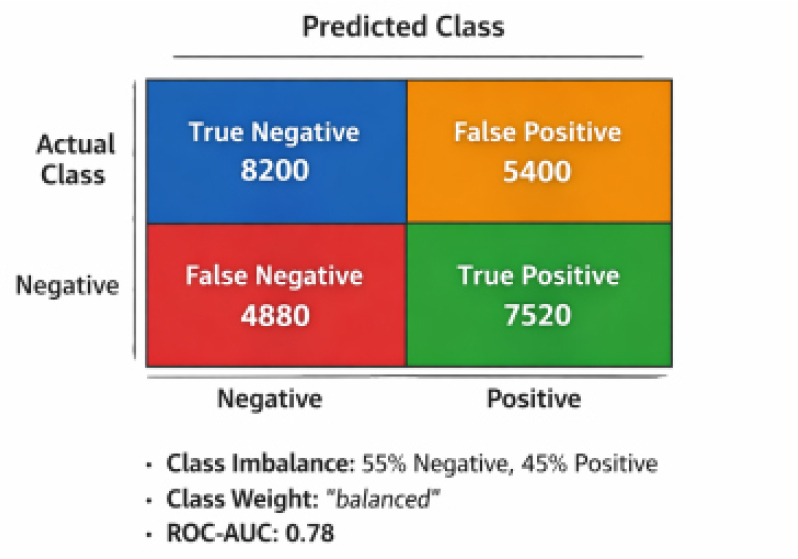
Where Figure 9 presents the confusion matrix of the proposed Gradient Boosting model, illustrating the distribution of true positive, true negative, false positive, and false negative predictions. The matrix confirms that the model maintains a balanced prediction performance across both classes, with agood trade-off between sensitivity and specificity. This further supports the reliability of the proposed system for real-world clinical screening and early risk assessment of cardiovascular disease.
Interpreting Model with SHAP
The interpretability of machine learning models in medical decision-support systems is critical for establishing clinical trust, transparency, and validation of predicted outcomes. In order to characterize the decision-making process of the selected Gradient Boosting model, SHapley Additive exPlanations (SHAP) were used to quantify each of the input features’ contribution to the final prediction. The SHAP framework provides a common, theoretical way to quantify the effect of each of the input features on the model’s output at both the global level and for each prediction.
The SHAP summary plot (Figure 10) indicates the rank of the features based on their overall contribution and influence on predicting cardiovascular disease. The feature that had the largest impact on the prediction of cardiovascular disease was systolic blood pressure (ap_hi), followed by cholesterol level, age, glucose level, diastolic blood pressure (ap_lo), and body weight. These features had the highest overall contribution to the model’s decision-making process and correlate with the established clinical risk factors for cardiovascular disease.
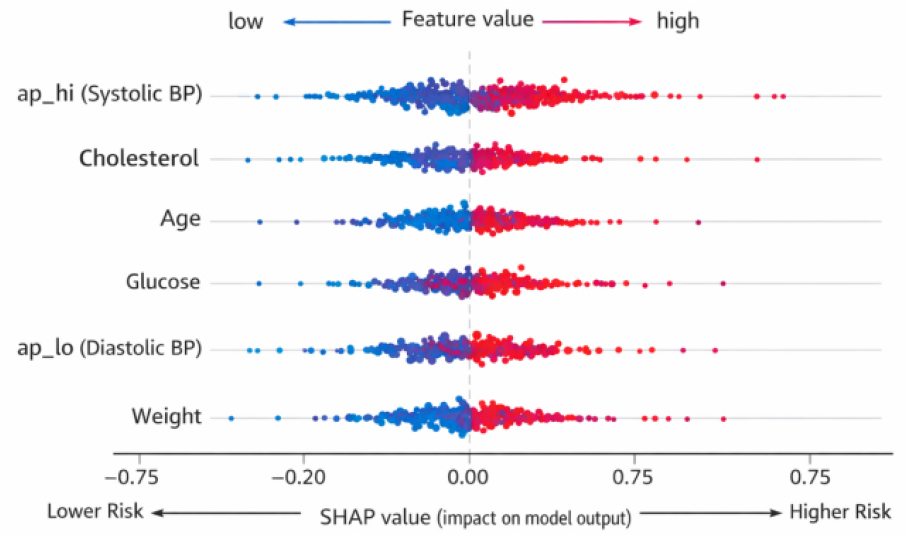
Higher values of systolic and diastolic blood pressure, elevated cholesterol and glucose levels, and increased age and body weight were found to positively contribute toward the prediction of cardiovascular risk, whereas lower values of these parameters reduce the predicted risk. which is represented in the classification of cardiovascular risk factors as shown in Figure 11. This analysis shows that the Gradient Boosting algorithm achieves high predictive power for identifying individuals who are likely to develop CVD, while its ability to provide an explanation for how it predicts these individuals’ risks provides assurance that the criteria used to arrive at predictions are clinically valid and applicable to real life applications of smart health care system.
Performance evaluation result of classification on varied number of datasets
Gender emerges as an important factor influencing cardiovascular prognosis in the case studies. Men represented by gender=2 show a greater propensity for cardiovascular disease, as evidenced by tables 1, 3, 5, and 7. However, only gender is indicative of the presence of disease, as seen in columns 2, 4, 8, and 9, 10, while females (gender =1) also exhibit disease patterns. Age plays an important role, with older individuals being more susceptible to cardiovascular events, highlighted by datasets 2, 3, 5, and 7. Blood pressure measurements (ap_hi and ap_lo) provide insight significant, with higher levels associated with increased risk of disease in lists 3, 5, 6 and 7. Cholesterol and glucose levels (table 2, 3 and 7) are additional indicators, with higher readings indicating higher risk Lifestyle factors such as smoking and alcohol consumption (table 3, 5, and 7) contribute to disease propagation, whereas physical activity levels (data set). 6) may offer some protective benefits Overall, the interaction of these factors highlights the multifaceted nature of cardiovascular prognosis, emphasizing the importance of comprehensive risk assessment emphasize as shown on Table 3.
Table 3.
Predictive Factors Analysis for Cardiovascular Disease across Diverse Demographics
Conclusion and Future Scope
Premature mortality from CVDs continues to pose a major global health challenge, underscoring the need for robust, secure, and responsive digital healthcare systems integrated within sustainable living environments. Blockchain technology plays a pivotal role in this context by ensuring reliable storage, traceability, and confidentiality of patient health records, thereby strengthening trust in data-driven healthcare solutions deployed across smart buildings and urban infrastructures. The primary aim of this research is to develop an efficient cardiovascular disease prediction model and a smart, emergency–notification application that leverages blockchain-based decentralized medical storage to address long-standing concerns regarding data integrity and secure health information management. Accurate forecasting is essential for modern urban healthcare systems, particularly as cities transition toward sensor-rich, health-supportive built environments. To achieve this, the proposed framework employs the Gradient Boosting (GDB) algorithm for efficient CVD prediction using securely stored patient data within a blockchain network. Complementary machine learning models including Support Vector Machine (SVM), k-Nearest Neighbour (KNN), and Random Forest were also evaluated, achieving a maximum prediction accuracy of 73.64%. These results demonstrate the transformative potential of integrating advanced ML frameworks with secure data architectures and IoT-driven monitoring systems within smart and healthy buildings.
Although the results are promising, further research and modifications are clearly needed. Increasing our understanding of the complex dynamics of CVDs, including factors such as genetic predisposition, social selection, and environmental influences, is improving our technology to increase the predictive accuracy of the study model which can be achieved by including additional variables in our analysis. Adopting an interdisciplinary approach holds the key to developing more accurate risk assessment tools and intervention strategies for cardiovascular disease.
