

Introduction
Literature Review
Research Gaps and Motivation
Methodology
Problem Statement
Proposed Methodology
Mathematical Model
Results and Discussions
Performance Metrics
Results
Conclusion
Introduction
Sustainability in the times of a fast digital revolution means more than merely taking care of the planet. It is also inclusive of technology, economics, and society. Social networks and intelligent urban ecosystems define the modern life. These systems generate vast quantities of dynamic information of persons, societies, and smart devices. They determine what we ultimately decide, communicate and how we care about one another. Digital ecosystems, i.e. smart-city applications, e-governance, e-commerce, and social media, are the platforms that influence choices, communication, and health. In that regard, to construct sustainable and human-centric social networks, it is necessary to provide intelligent, context-sensitive, and emotion-sensitive recommendations [1, 2, 3, 4, 5].
Recommendation systems control information flow between digital and social platforms. They minimize the overloads, enhance resources utilization, and promote meaningful interaction. Recommendation engines connect people, data, and services whether it concerns the suggestion of eco-friendly transport in a city, custom-crafted study material, or useful online contacts. In the past, collaborative and CBF were utilized as a way of personalization. These techniques have problems of data sparsity, scaling issues and cold-start in social networks. They also lack the touch and scenery during interaction with user’s opinions, emotions, trust. The inclusion of SA is a revolutionary solution. SA is a sophisticated NLP tool that retrieves emotional expressions within the reviews, posts and comments. It has been used in conjunction with behavioural and relational models to allow the recommendation systems to know the intent of the user, his or her mood, and the community dynamics. This provides socially and emotionally intelligent outcomes [5, 6, 7, 8]. This integration is enhanced by Deep Learning (DL). Semantic, relational and affective patterns in social data are automatically learned by Convolutional Neural Networks (CNN), recurrent networks and transformer models such as BERT, RoBERTa etc. Incorporating them into the hybrid recommendation systems balances behavioral, relationship and sentiment elements. The outcome is an increase in accuracy and the user trust and cohesion in online communities. Sentiment-aware systems facilitate digital well-being in terms of sustainability. They make AI human, enable responsible governance, and smart consumption giving contextually, emotionally-relevant suggestions, which conform to the objectives of smart city and sustainable development [8, 9, 10, 11].
The proposed sentiment aware hybrid deep-learning architecture on sustainable smart urban and social network ecosystems has a conceptual architecture as displayed in Figure 1. The architecture is designed with the five consecutive layers that are all the data- processing and learning workflow of the system. The first step is to input data using input layer for pre- processing. This information is then forwarded to Pre- processing and Feature Extraction Layer where it is cleaned, normalised and converted. This step uses pre- trained transformer models, like BERT and RoBERTa, to obtain sentiment and contextual embeddings of social text and other behavioural and structural features are obtained as a result of user-item and user-user interactions. The Hybrid Recommendation Layer is a unification of CBF and collaborative methods that assemble the user preferences and item resemblance. In this layer, sentiment and social context are merged to enhance personalization and the emotional and social nature of user behaviour [10, 11, 12, 13, 14, 15, 16, 17].
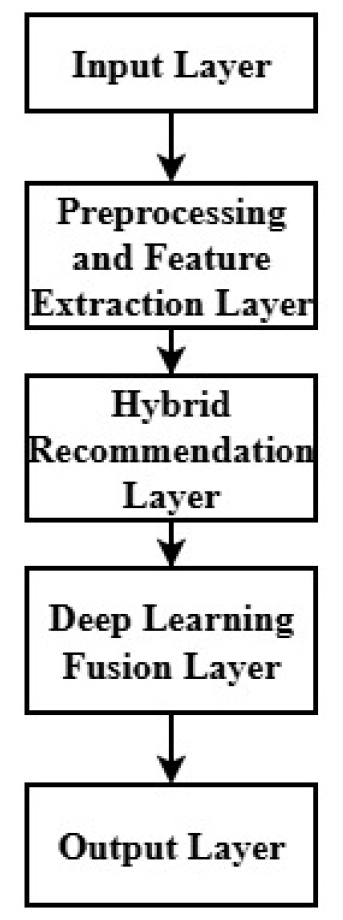
The DL Fusion Layer splices all the extracted features with nonlinear learning processes, which enables the model to resolve the complicated association between behavioural, content, and sentiment- based representations [18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30]. Lastly, the Output Layer produces context-aware, socially relevant, and sustainability-based recommendations, which may be implemented in the smart-city services, digital platforms, and social networks. All in all, the framework illustrates the potential of hybrid DL and SA to support the accuracy, flexibility and sustainability of recommendation system in smart and socially integrated digital ecosystems [31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45].
This paper presents a hybrid DL framework that can be used to satisfy the needs that arise by introducing a sentiment-aware hybrid deep-learning framework to address the need of smart urban and social-network ecosystems that are also sustainable. This framework integrates transformer-based SA, CBF and CF to utilize both the user behavior and social interaction data. The model compromises the efficiency of computation with social insight by combining both structured user behavior and unstructured sentiment of the social websites. The framework can enhance individualization, confidence as well as sustainability in online settings, the experiments demonstrate [46, 47, 48, 49, 50, 51, 52, 53].
The organization of the paper is presented in the following way. Section 2 conducts a literature review on the topic of recommendation systems, DL, and SA as it relates to social networks. Section 3 illustrates the framework and methodology of the hybrid framework proposed. In Section 4, the results of the experiment and the performance evaluation are made. Section 5 is the last part of the study as it summarizes the main contributions and provides the direction of future research. This is to enhance socially intelligent, sentiment intelligent, and community intelligent recommendation systems, reinforcing sustainable digital and urban ecosystems with adaptive, emotion intelligent, and community intelligent intelligence.
Literature Review
The latest innovations in the domain of artificial intelligence reshaped the human behavior and emotion interpretation of the recommendation systems. Li et al. conducted a review of DL-based recommendation models and stated that the field is dominated by neural architectures since they have the ability to reveal latent correlations in multi-dimensional user-item data. Following this tendency, Jassim et al. reviewed the method of SAof film review and divided the currently existing methods into three large groups: lexicon- based, ML-based, and hybrid, pointing out the increased importance of the combination of linguistic and statistical understanding in more precise polarity interpretation. A CNN-LSTM based recommendation system of tourist destinations was proposed by An and Moon, which demonstrated that deep neural networks can be used to map textual feedback and contextual clues, such as season or weather to personalized recommendations.
In the same vein, Babu and Kanaga examined SA of social-media data to identify depression and found that both binary and multi-class classification methods could be useful to identify subtle changes in emotions, as expressed by users.
Rosa et al. developed a mental health monitoring system based on knowledge that incorporates ontologies, DL, and SA. The research demonstrates that emotional knowledge can improve the quality of the recommendation in the health setting.
Nair et al. made a comparative study of sentiment- based models of recommendation with various platforms and found out that sentiment mining through opinion mining has a great contribution to relevancy in recommendations.
In the agricultural sector, Sharma et al. came up with a sentiment-based product recommendation model of managing the rice-crop diseases. Their work demonstrates how these techniques can be used in other industries that require contextual decision support, rather than in e-commerce.
Loukili et al. were concerned with product reviews in online retailing and they found that unstructured textual responses are very crucial in influencing consumer choices. Their study supports the need to transform unprocessed reviews into formatted sentiment knowledge to enhance product recommen-dations.
Gupta et al. synthesized several ML models to evaluate aspect-based sentiment through the application of ML, which showed that integrative models are more interpretable and accurate as compared to solitary- model approaches.
Sellamuthu et al. introduced an AI-based model of recommendations that can be utilized to predict drug interactions and enhance decision-making during pharmaceutical research. The paper demonstrates how recommendation systems can be flexible in the process of scientific uses. Cui et al. gave a general overview of the development of SA studies. They observed a steep rise in hybrid and transformer-based models that are more effective than previous statistical methods. Okey et al. explored how the sentiment tracking can evaluate trust and risk in new technologies by investigating SA and topic modeling of ChatGPT perception in the community. Kaur and Sharma suggested a DL model, which incorporates hybrid features and LSTM networks to provide an overview of consumer views. Lastly, Sharma et al. overviewed SA tasks and DL approaches to a variety of domains, discovering the main problems of sarcasm detection, the ethical utilization of data, and the ability to adapt to new language environments. A DL-based basil leaf disease classification framework was suggested by Singla et al., which applies transfer learning to improve agricultural sustainability; the CNN-based models are effective in detecting plant diseases, encouraging effective resource management and precision agriculture, which is a significant component of sustainable smart ecosystems. Sharma et al. proposed a ML-based system of energy-efficient load distribution of mobile edge computing (MEC) systems, which streamlines resource allocation and consumption. This paper illustrates the way ML can contribute to the smart city and building environments to meet the sustainability objectives, which is consistent with the development of intelligent infrastructure. Likewise, Sharma and Kamra used a hybrid approach or a combination of ML and image segmentation in mammographic diagnosis to enhance the accuracy of the detection at minimum computational cost.
Research Gaps and Motivation
Current studies of sentiment analysis, hybrid recommendation systems, and transformer-based embeddings also have significant drawbacks. First, the majority of transformer-enhanced recommenders do not focus on emotion-conscious personalization that facilitates human-centered digital sustainability, but are focused on accuracy. Second, collaborative filtering and content-based filtering with sentiment embeddings have only a few studies that use deep fusion, which restricts whole contextual reasoning. Third, existing models do not list computational cost or resource use, or long-term digital well-being, which are important sustainability parameters. Lastly, the majority of assessments operate on small, domain- specific datasets, thus, it makes them less generalized and robust. The comparison of current methods, datasets, limitations, and performance is summarized in Table 1.
Table 1.
Performance comparison of existing techniques used in literature
| Author / Year | Technique / Model | Dataset / Domain | Accuracy / Performance | Key Contribution | Limitation |
| Li et al. (2023) [11] | DL–Based Recommendation Review | Multiple Benchmark Datasets | – | Provided taxonomy of DL-based models for recommendations | Lacked focus on sentiment integration |
| Jassim et al. (2023) [12] | Lexicon + ML Hybrid Sentiment Model | Film Review Dataset | 92.50% | Proposed hybrid SAcombining lexicon and ML | Limited domain coverage, no contextual DL |
| An & Moon (2022) [13] | CNN–LSTM Framework | Tourism Recommendation | 93.40% | Integrated contextual features like weather and season | Did not incorporate affective sentiment features |
| Rosa et al. (2018) [15] | Knowledge-Based + Sentiment Deep Model | Psychological Well-Being System | 94.00% | Introduced affective feedback in health recommendations | Narrow domain; not scalable to large social networks |
| Nair et al. (2021) [16] | Sentiment-Based Hybrid Model | Multi-Platform | 95.20% | Demonstrated opinion-mining–driven personalization | Limited model generalization |
| Sharma et al. (2024) [17] | Sentiment-Aware Agricultural Recommendation | Crop Management | 96.00% | Applied SAto agri-sustainability | Domain-specific; lacked deep contextual embedding |
| Karabila et al. (2024) [25] | BERT-Enhanced Sentiment Model | E-Commerce Reviews | 92.00% | Used transformer embeddings for personalization | Focused on item-level analysis only |
| Ojo et al. (2023) [30] | Graph Neural Network (GNN) + Sentiment | Smartphone Recommendation | 97.00% | Incorporated graph-based user relationship modeling | High complexity, lower scalability |
| Proposed Framework (2025) | Hybrid DL + Sentiment (BERT, RoBERTa) | Smart Urban & Social Network Ecosystems | 99.14% Accuracy, 99.52% F1-Score | Combines behavioral, contextual, and affective intelligence for sustainable, human-centric recommendations | Addresses previous gaps in scalability, context, and emotional adaptability |
The proposed framework will fill the gaps by:
1.Combining transformer-based sentiment repre- sentations and hybrid CF-CBF predictions through a deep fusion mechanism.
2.Integrating emotion-sensitive and context-sensitive cues into relevance scoring of recommendations.
3.Huge validation of performance of large and heterogeneous data sets and statistical reliability testing.
Methodology
In this section, the methodological framework will be presented to design and develop a hybrid DL and SA recommendation framework. It gives insights on the way user interaction data and textual reviews are combined to form an intelligent system that can produce personalized, sentiment-aware recommendations.
Problem Statement
Recommendation systems play an important role in sustainable digital ecosystems, i.e. smart cities, intelligent infrastructure, and environmentally friendly digital platforms, to enhance user experience, resource optimization, and assist in decision-making. However, the most popular models, ones that are primarily based on CF and CBF, are not able to comprehend the underlying human intent and their emotional context. They are relying on numeric scores or even transaction records, which restrict personalization, interpretability, and flexibility. Due to these flaws, these models are wasteful of digital resources, they inattentively engage users, and they consume additional computing resources. This is contrary to the objectives of developing sustainable systems. The inefficiency implies that every recommendation request consumes more energy and bandwidth than it is needed, which decreases the sustainability. The other problem is the cold-start problem. The lack of sufficient data to train the model happens when new users or new items are introduced, which reduces scalability and causes redundant and repetitive processing. This also adds to the wastage of computational power. In order to transcend these constraints, this paper introduces a DL hybrid recommendation engine that is emotion aware. It incorporates SA as an element of personalization. The model uses behavioral data, contextual and affective signs to provide more sustainable, efficient, human- centered and adaptable recommendations to changing user needs.
Proposed Methodology
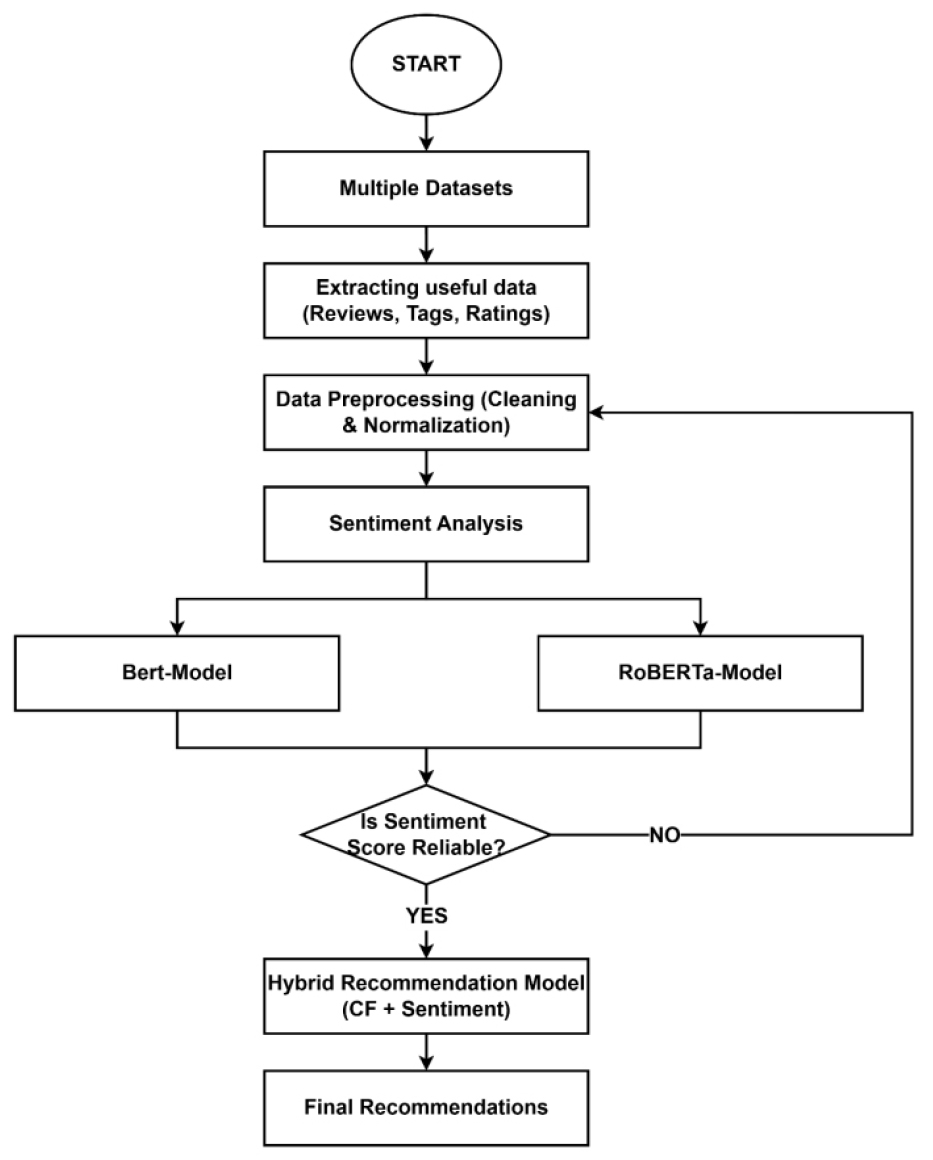
Figure 2 represents the proposed framework and is a recommender based on deep-learning hybrid that incorporates SA to provide smarter and more personalized recommendations. It is a mixture of three fundamental concepts, which are CF, CBF, and neural models to understand emotion in user reviews. Combined, the approaches enable the system to anticipate the liking of the users and simultaneously comprehend their perceptions on their experiences. The process begins with the data collection which includes online stores, movie platforms and social- media sites where the user can leave out their reviews and ratings. There are two types of data that include structured data which consists of numeric ratings and user IDs, and unstructured data which consist of written reviews, comments, and tags. The combination of the two types helps the system to learn better and be performed in different situations. The system then filters and isolates the most informative features: reviews, tags, and ratings after collecting the information. Reviews include the emotional and opinion of the users, tags suggests the kind of content, and ratings offer a straightforward content of satisfaction. Focusing on this information will enable the model to understand the actions and emotions of the users. Pre-processing is the second step involving cleaning of the data. This is done to eliminate extraneous symbols, redundant space and filler words, to normalize the text format. Tokens are divided into sub units and variations in spelling corrected. After cleaning the data, the system carries out SA that determines the emotion in the review. It reviews the tone of the text as positive, negative or neutral. This is performed using two Deep-learning models, which are BERT and RoBERTa. With the implementation of both models, reliability is enhanced and in case one presents uncertain result, the other goes back to the text. This check and cross-check eradicate errors and only reliable sentiment scores proceed.CF analyses the activity of users and compares it to suggest things that are liked by other users. CBF compares the characteristics of items and compares them with the items that were liked before. Then the engine incorporates the sentiment data: when the sentiment is positive, the recommendation is strengthened and when it is negative, the recommendation is weakened. The ultimate results of this blend are data-driven and emotionally informed and are more realistic in their suggestions. Lastly, the system generates a list of suggested items which is personalized. These suggestions rely on the combination of user behaviour, item specifications as well as emotional tone. The system is more satisfying and customized as it matches what the users have previously liked with the way they feel about their decisions.
Mathematical Model
The hybrid recommendation framework proposed is a combination of three basic systems such as CF (CF), CBF and SA. All these elements provide a new perspective to the process of recommendations. The end result is a composite score that will combine behavioral, contextual and emotional information to provide very personalized recommendations. Let the dataset be represented as:
where is the set of users, is the set of items, is the user-item rating matrix, and is the set of textual reviews associated with user-item pairs.
Algorithm 1.
Hybrid Recommendation Engine with SA
Each user can be represented by a vector of their preferences, and each item by its content-based attributes and textual reviews.
For each review , the pre-trained DL model (BERT or RoBERTa) predicts sentiment probabilities:
The overall sentiment score is computed as:
This score represents the emotional polarity of the review. The sentiment value is then normalized to a range [0, 1] to ensure uniformity:
The normalized sentiment score serves as a confidence-weighted indicator of user emotion and is later combined with other recommendation signals.
CF focuses on user-item interaction patterns. The predicted rating for a user on an item is estimated using a weighted average of ratings from similar users:
Here, is the average rating given by user , is the set of users similar to , and represents the similarity between users and . Cosine similarity is often used for this measure:
In CBF, recommendations are made using the similarity between the attributes of items and the preferences of a user. Each item has a feature vector (derived from metadata, tags, or descriptions), and the user profile represents the user’s interest distribution across these features. Table 2 summarizes the symbols, variables and mathematical representations used in the proposed model.
Table 2.
Notation Table
The content-based predicted rating is computed as:
where is the importance weight of feature , and measures how closely the feature matches the user’s profile.
To combine the benefits of both CF and CBF while introducing sentiment information, a hybrid scoring function is used:
where 𝛼, 𝛽, and 𝛾 are non-negative weights such that 𝛼+𝛽+𝛾=1. The model takes into consideration emotional background by considering the sentiment hence it reacts to user moods and experience.
For each user , the model calculates for all items . The top- items with the highest scores are then selected as recommendations:
This step gets out the most relevant items as well as the emotionally matched items of each user.
In the training process, the loss function:
where 𝛩 denotes the model parameters and 𝜆 is the regularization coefficient to prevent overfitting. Optimization is performed using Stochastic Gradient Descent (SGD) with momentum:
This ensures stable convergence and efficient learning of model parameters.
The proposed model integrates the behavioral, contextual, and emotional findings into one recommendation score. It is able to increase the accuracy, personalization and emotional relevance in recommendations by combining deep-learning sentiment extraction with the more traditional CF and CBF. Table 3 indicates the chosen hyperparameters and their experimentally confirmed values to train the model.
Results and Discussions
In this section performance comparison of proposed framework with state of art techniques has been discussed. The proposed framework has been implemented using Python on Google Colab. The computation speed and time of training were also improved due to the use of the GPU in the platform. The dataset utilized for performance evaluation is Sentiment- Based Product Recommendation and Reviews. This sample contains approximately 12,000 user reviews that have been labeled. By comparison, MovieLens provides more than 33 + million ratings and 2.3 + million tags of approximately 331 000 users and 86 000 movies. Both datasets underwent text cleaning and token normalization, as well as stop-word elimination, and transformed corpus with the maximum sequence length of 256 tokens using transformers. The dataset is accessed through Kaggle. The dataset has numerous user-generated reviews and product ratings, which make it the best to test sentiment-based recommendation models. All records contain user ID, product ID, a rating and a textual review. The product variety in which reviews are performed gives the model a wide exposure to different sentiments and purchasing trends. Since the reviews are mixed with a positive and negative comment, they can be used to train and justify sentiment-analysis modules. A combination of structured fields and unstructured text gives a good foundation on the development and testing of hybrid recommendation systems that integrate emotional context and well-known rating predictions. Table 4 indicates the system structure and calculation design of the model implementation. Furthermore, the attributes of the dataset are summarized in Table 5.
Table 4.
Experimental Environment
| Component | Configuration |
| Platform | Google Colab Pro+ |
| GPU | NVIDIA Tesla T4 (16GB VRAM) |
| CPU | 2.30 GHz × 4 Cores |
| RAM | 25 GB |
| OS | Ubuntu 20.04 |
| Libraries | Python 3.10, PyTorch 2.1, Transformers 4.33 |
Table 5.
Description of the Sentiment-Based Product Recommendation and Reviews dataset
The analysis is based on the MovieLens Latest Full dataset that consists of more than 33 million user ratings as well as approximately 2.3 million tag applications. It has 86,000 movies that represent approximately 331,000 different users. The data are put in three CSV files rated in ratings.csv, movies in movies.csv and tags in tags.csv. The files are a record of a dissimilar aspect of user-item interaction. Behavioral and content-based analyses are based on these files. The dataset is a combination of numerical, textual, and categorical data, allowing CF relying on it, as well as sentiment-based approaches. The usage of the dataset is described in a Table 6.
Table 6.
Description for the attributes of the dataset
Performance Metrics
Accuracy is the proportion of the accurate forecasting to all the predictions of the model. It gives us the overall recital of the model. The accuracy is however misleading, particularly on unbalanced data sets, where one class is predominant, as a model can be highly accurate merely by voting in the majority class.
Precision is the proportion of accurate and all predictions called positive by the model. It demonstrates the ability of the model to avoid false positives. Precision is very important in cases where a false positive classification might have grave repercussions or a false declaration.
Recall, depict sthe proportion of the correctly detected positives divided by the total actual positives is referred to as the proportion of the true positives. This measure is particularly crucial when a positive result is missed which might cause essential mistakes or undesirable outcomes.
The harmonic mean of precision and recall is the F1. It provides an objective picture of the performance of a model. The measure is applicable when both false positives and negative are significant. It is good in case of uneven distributions of the classes as there is a reasonable assessment of the prediction given by the model in all the classes.
Results
In Figure 3, the confusion matrix of the baseline sentiment classification model is used. It made only 33 false positives and 68 false negatives which is a very low rate of error.
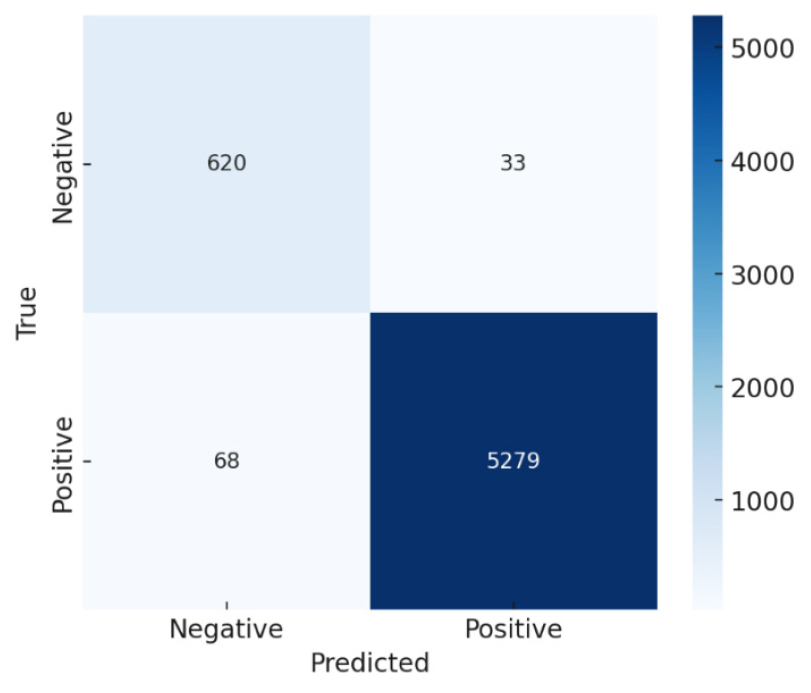
This means that the model is accurate, and it detects most positive sentiments but it has a limited number of errors. Although some of the positive feedbacks were marked as negative, the overall accuracy of approximately 98.8 3 appears to be balanced between the precision and recall. These results verify that the model is effective to record the most important patterns of sentiments and give a strong base to the enhanced hybrid system of recommendations.
The confusion matrix of the optimized sentiment classification model is shown in Figure 4 and the accuracy of the model was approximately 99.14. Based on approximately 12,000 samples, the model was able to identify 10,647 positive cases and 1,250 negative cases and false positives and false negatives were only 28 and 75 respectively. These results indicate very high classification and are lowly in error. The extremely low percentage of error of classification shows how effective the suggested hybrid approach is in learning and differentiating the sentiment polarity. The fact that the system is accurate in both positive and negative forecasts is also indicative of its stability, robustness, and scalability and it is therefore effective in large-scale sentiment-based recommendation tasks.
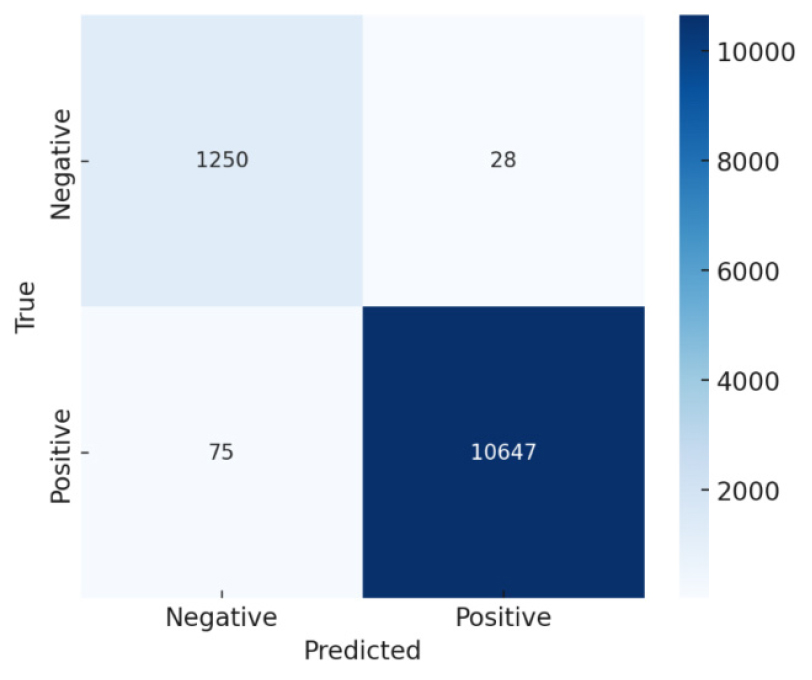
Figure 5 and Table 7 reflect the performance of the initial version of the sentiment-classification model. It has average accuracy of about 98.78. The model has been identified as very good at identifying the appropriate sentiment patterns. Recall is slightly higher than precision that is, it picks the majority of the positive cases although some false positives are also generated. F1-score, a metric that gives a balance amid precision and recall, shows that there is a healthy trade-off between the two. In general, the findings verify that the model is effective and consistent, which provides a good foundation to include SAto the hybrid recommendation framework.
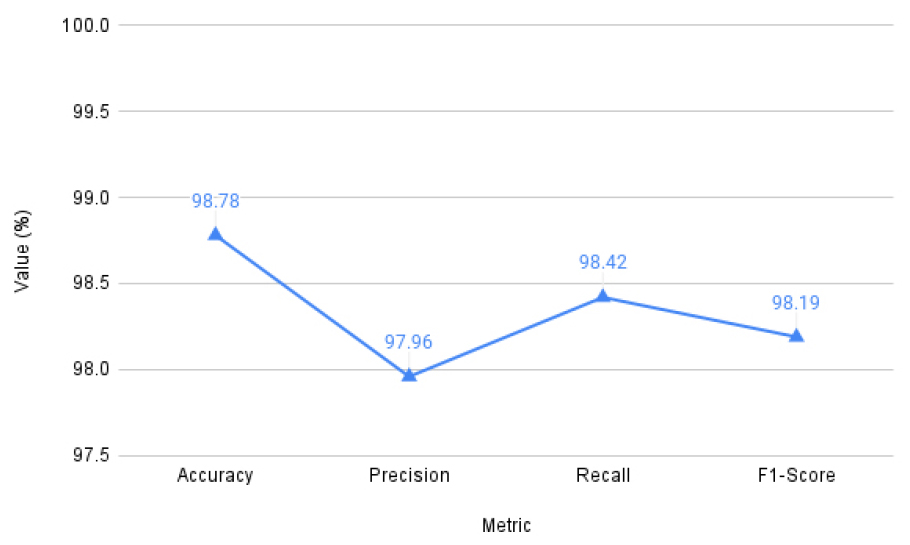
Table 7.
Metrices value of the proposed work on dataset-1
| Metric | Value (%) |
| Precision | 97.96 |
| F1-Score | 98.19 |
| Recall | 98.42 |
| Accuracy | 98.78 |
The results of the assessment of the improved model are presented in Figure 6 and Table 8 and have the accuracy of approximately 99.14. The almost flawless accuracy and recall rates indicate that the model is capable of distinguishing amid positive and negative sentiments with an enormous degree of accuracy. F1-Score 99.52-percent shows that there was a good trade-off on the true positives and the false classification. This is an enhancement of the earlier version, as the model has a higher capability to generalize to a larger dataset and still achieve a high performance.
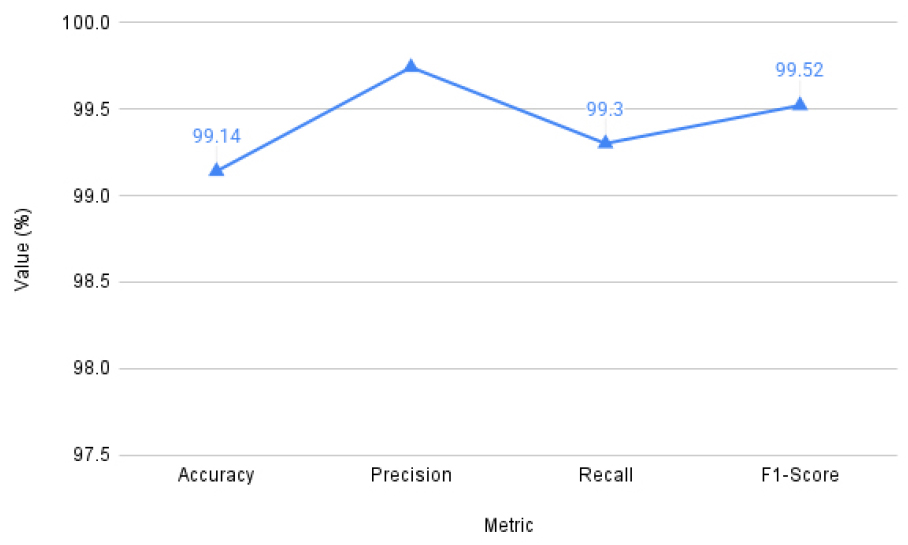
Table 8.
metrices value of the proposed work on dataset-2
| Metric | Value (%) |
| Precision | 99.74 |
| F1-Score | 99.52 |
| Recall | 99.3 |
| Accuracy | 99.14 |
Figure 7 illustrates the accuracy of the four models sucha as Karabila et al., Hameed and Zapirain, Pan and Liang, and our proposed framework. Hameed and Zapirain stated that BiLSTM model had an accuracy of approximately 0.89, and BiGRU model by Pan and Liang gave an accuracy of approximately 0.91. Karabila et al. achieved a slightly better accuracy, namely 0.92. Our model had the best accuracy of 0.95 which is a significant improvement of 6.7 and 4.4 and 3.3 relative to BiLSTM, BiGRU and Karabila et al.. These results underscore the excellence of our model in terms of its capacity to predict sentiment patterns with appropriate accuracy and give sound recommendations.
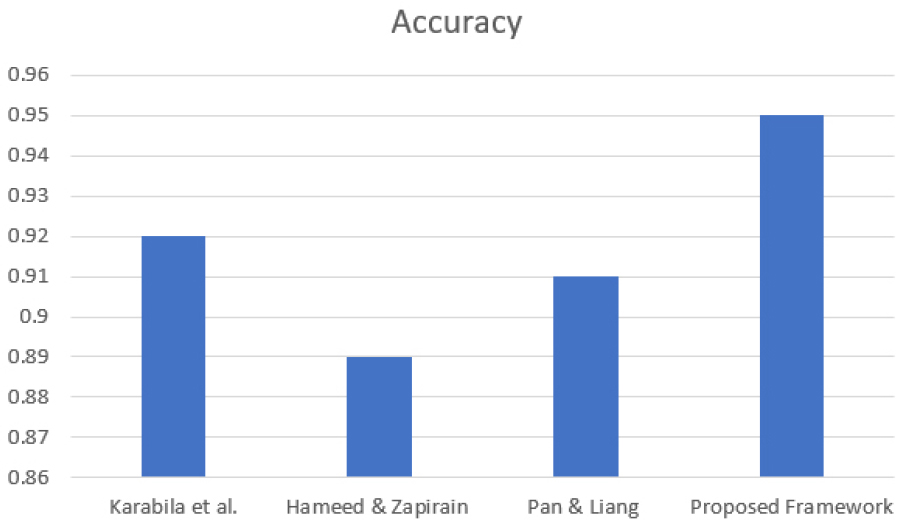
Figure 8 shows the comparison of the F1 -score of four frameworks. The F1-score is used to balance the precision and recall to provide a whole picture regarding the classification effectiveness of a model. A mean F1-score of 0.89 was obtained by Hameed and Zapirain using a BiLSTM architecture. A BiGRU was used to increase the score to 0.91 by Pan and Liang. Karbali et al. received a little more value of 0.92, which would denote a moderate improvement. Our framework achieved a score of 0.95, and it was always higher than all other works. The decrease in error of misclassification and highly effective generalization of this model proves its usefulness. These results prove that the suggested system is more balanced in terms of sensitivity and precision than the approaches it was contrasted with Figure 8. Comparison of AUC-score of the existing techniques on Dataset-1. Figure 8 demonstrates four frameworks AUC scores. AUC is used to determine how a model can differentiate between positive and negative sentiment. Hameed and Zapirain also achieved an AUC of approximately 0.70 with their BiLSTM. Using a BiGRU, Pan and Liang increased this to 0.80. Karabila et al. developed an even larger AUC of approximately 0.85 showing improved class separation. Our proposed framework performed significantly better than any other model in the past with AUC of 0.95: 35.7 per cent higher than BiLSTM, 18.8 per cent higher than BiGRU and 11.8 per cent higher than Karabila et al. These gains demonstrate the fact that our architecture is more resilient and discriminating sentiment when it comes to recommendation tasks.
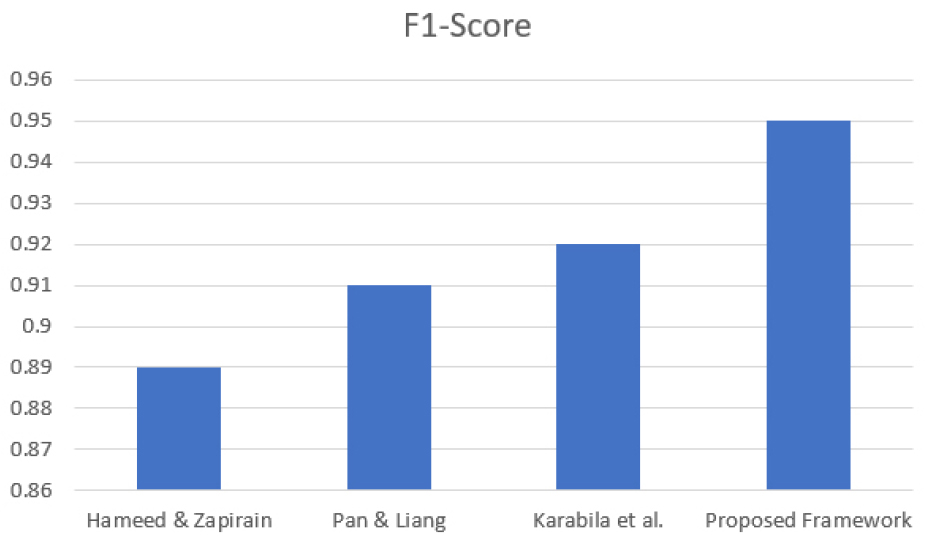
Figure 9 and Table 9 shows a comparative evaluation of four frameworks such as Sekaran et al., Singh et al., Ojo et al., and the proposed methodology. The proposed approach is more stable and efficient at producing sentiment-based suggestions and, therefore, it always has better results in all of the metrics compared to others.
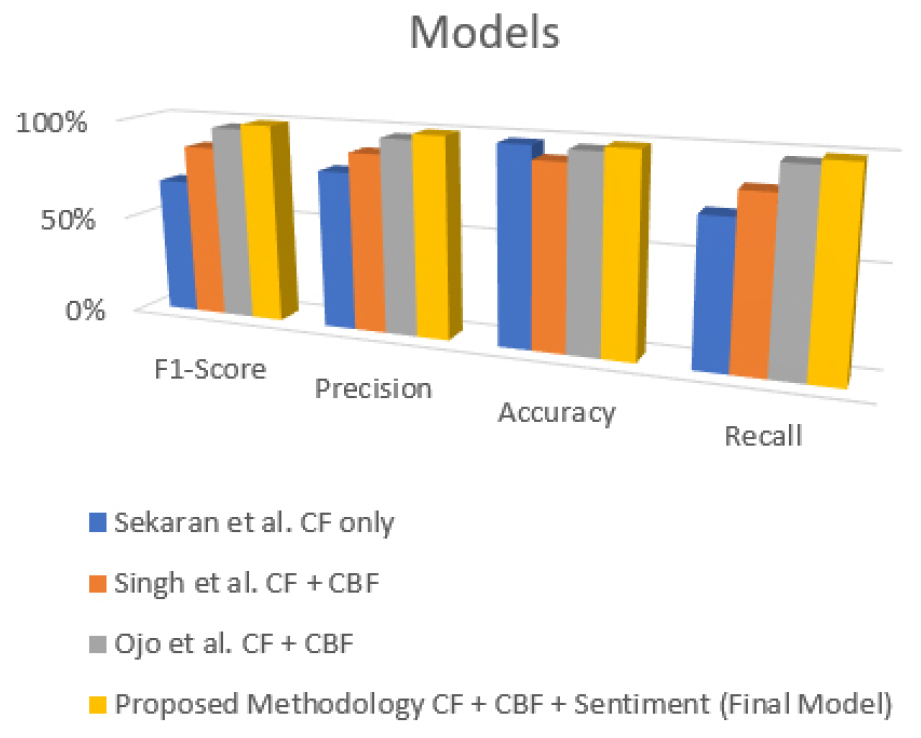
Table 9.
Assessment of proposed framework with existing techniques on Dataset-2
S ekaran et al. obtained lesser metric values, where precision, recall and F1-score decreased significantly below 80%. This means that there was less consistency in classification accuracy albeit with moderate accuracy. Singh et al. have done slightly better, maintaining most of the metrics at above 85%, although recall was inadequate, indicating that they are not able to capture all the instances of sentiment of interest. Ojo et al. demonstrated consistent performance and the accuracy and recollection of about 95% and are representative of the balanced classification. Conversely, the presented approach recorded almost perfect results, with all the four indicators of about 99%. The proposed model works more effectively primarily due to its combination of sentiment data. This allows it to examine behavioral and content relating similarities as well as the emotional resonance of user response. It identifies nuanced sentiment within the context that is absent with traditional CF and CBF approaches through transformer embeddings such as BERT and RoBERTa. The sentiment signal then increases or decreases scores on recommendations depending on actual user emotions eliminating irrelevant suggestions and enhancing accuracy. A deep fusion layer models non-linear correlations between behavior, content, and affective cues, is more accurate, robust and less sparse and cold start compared to traditional methods.
In addition to performance, we address the sustainability of the framework in relation to the digital well-being perspective. Our interpretation of sustainability is based on digital and social welfare and not environmental figures. Sentiment-aware hybrid learning is expected to reduce redundant recommendations, increase user experience, and foster emotionally engaging online interactions, which are the values that sustainability of smart-urban ecosystems are supposed to be. Although we now define sustainability conceptually, next generation research will include quantifiable measures such as user-experience outcomes, computational cost, and scalability of deployment to determine its effect.
Conclusion
The sentiment-aware DL system integrates collaborative, content-based, and transformer-based sentiment analyzes into a single architecture that aims at sustainable smart urban and social network ecosystems. It is able to do this by exploiting advanced transformers like BERT and RoBERTa to extract both behavioral and affective user preferences, which generate highly accurate, context-sensitive, and human-centric suggestions. The results indicate that the framework is more effective than traditional techniques since it scored 99.14% accuracy and 99.52% F1-score, which proves its strength, flexibility, and efficiency. Besides predictive accuracy, the framework will enhance digital and social sustainability through lessening computational load, enhancing user trust, and providing ethical, inclusive, and context-sensitive personalization.
