

Introduction
Link Prediction Problem
Applications of Link Prediction Techniques
Literature Review
Similarity Score based Link Prediction Techniques
Supervised Machine Learning Based Link prediction Methods
Other Link Prediction Approaches
Research Gaps
Factors and Parameters Affecting the Missing Link Prediction in Social Network
Conclusion
Introduction
A social network is a structure composed of social actors, dyadic ties, and interactions among these actors [1]. It serves as a representation of the social hierarchy among the many social units. An individual or an organization might be considered a social entity. Social entities, also known as nodes, are linked to further nodes through associations, likewise recognized as edges, in online social networks [2]. The presence of an association or communication among the nodes is shown by these linkages [3]. A model social set-up is shown in Figure 1, with nodes standing in for social entities and connections for the interactions between them.
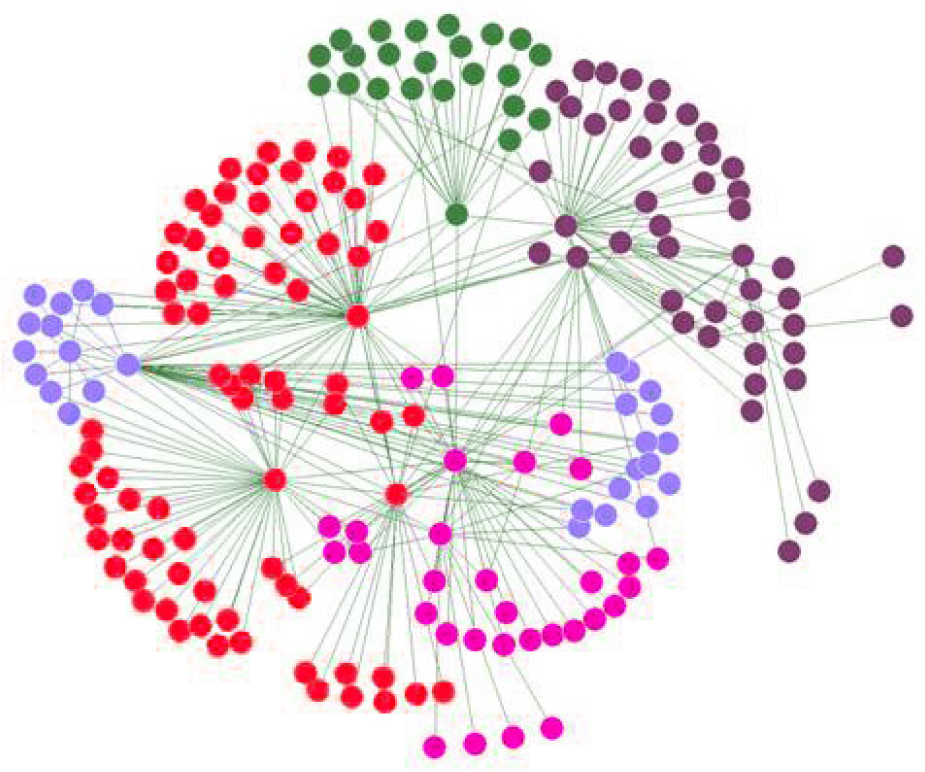
Figure 1.
Illustration of a sample social network where nodes represent social entities and edges denote interactions between them [1].
The use of online social systems has increased dramatically in the modern era. Millions of people have used it as a platform to communicate with one another about their ideas, opinions, and views [4]. In addition, political awareness initiatives, blogging, reviews, and marketing are conducted on this site [5]. Social networking platforms such as Facebook, Instagram, Twitter, and WhatsApp have become indispensable in daily life [6]. Social networks are inherently quite dynamic since they continue to expand (or change) throughout time [7]. A social system’s primary objective is to maximize the number of connections since this promotes efficient use of the services it offers and guarantees that information spreads quickly throughout the network [8].
Examining the relationships between two particular nodes will help to simplify this problem. The link prediction difficulty is the task of determining which relations among unconnected nodes in a social system are most likely to occur. It calculates the likelihood that two currently separated nodes may establish a link. Based on the nodes and connections that are currently in place, the chance is estimated. It is conceivable that a user is not linked to someone on a social network that he knows in real life. Therefore, in this case, the objective of the link prediction approach is to suggest a association among two people in the specified social network who are currently unconnected.
An essential component of all social networking sites is link prediction. The aim of link prediction techniques is to create as many associations as they can. Even if a completely connected network is unattainable, there are always techniques to increase the likelihood that users who are not connected can connect. The several domains in which link prediction algorithms are applied are revealed in Table 1.
Table 1.
Major application areas of link prediction techniques across different domains
This paper’s remaining sections are arranged as follows. The mathematical formulation of the link prediction issue is described in section 2. A variety of link prediction application domains are shown in section 3. The literature review is presented in section 4. Factors and parameters affecting the absent link prediction in social system are discussed in section 5, and the article is concluded in section 6.
Link Prediction Problem
An enormous graph can be used to depict an online social network, with each node (also known as a vertex) representing an individual and each edge (also known as a link) representing the relationship between two individuals.
A symmetric adjacency matrix A ∈ {0,1} of dimension N × N can be used to depict an undirected network with N nodes, where A_ij = A_ji = 1 specifies the presence of an edge among nodes i and j. Associations in online social systems are often constructed on shared interests between participants.
The connection estimate difficulty in online social systems may be described mathematically as follows: Let G is a graph with V denoting the group of persons and E the set of edges. The link among users x and y at any time instance, t0, is represented by an edge, e (x,y) ∈ E. G[t0] is the name given to the graph at time t0. Link prediction aims to identify edges that are absent at time t0 but are likely to appear at a later time t1 (t1 > t0). An illustration of a link prediction issue for a specific set-up is revealed in Figure 2. Six vertices and their connections (shown by solid lines) at time instance t0 are shown in Figure 2(a).
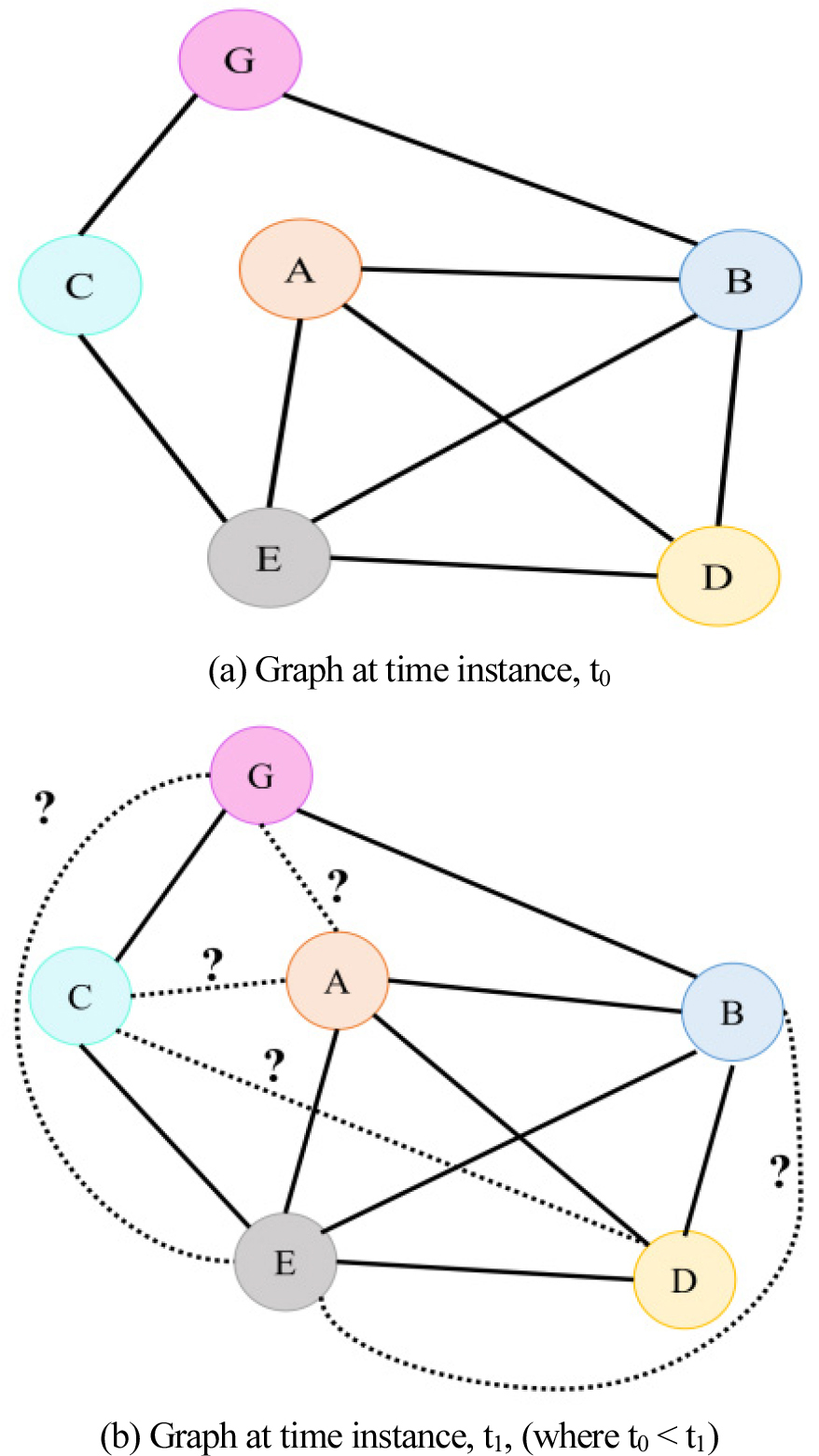
Figure 2.
Example illustrating the link prediction problem by showing existing and potential links between nodes at two different time instances [9].
Finding highly likely linkages between the unconnected node pairs (shown by dotted lines in Figure 2(b)) at time instance t1 is the goal of the link prediction approach. In an online social system, the link prediction difficulty is commonly considered as a twofold classification difficulty [9, 10]. One way to conceptualize the linkage forecast concern is as a challenge of classifying pairs of unconnected nodes as either “connected” or “not connected.” Usually, it is based on a resemblance score that is considered for every disconnected node duos in the specified network [11].
There is a significant coincidental that detached nodes with equal similarity scores may eventually link. Given the high grade of dynamic nature of social systems, link prediction, also known as forecasting, is a computationally difficult problem. The social network is constantly adding new connections and members.
Two categories can be applied to categorize link prediction issues centred on data availability:
a) future (or temporal) link prediction, or
b) disappeared link prediction
Future link prediction is the procedure of forecasting network structure at timestamp tk based on data available at timestamp ti if temporal data is available for two separate timestamps, ti and tk (where tk > ti). The link prediction concern, on the other side, may be treated as missing link prediction if temporal data is not provided. In this case, one can anticipate the present network topology by constructing random missing links. Since there are millions of nodes in an online social network, managing data becomes challenging when attempting to anticipate links. The adding or removal of nodes and edges on a regular basis causes a network’s topological features to change. These modifications suggest that, as a result of new link formation in online social systems, it is essential to investigate the dynamics of system topological features. The existence of class skewness (or imbalance) in the link prediction job is another problem. On Facebook, every user may connect to 1.35 billion other users [12], yet each person only links to a few hundred nodes on average in the social network. There is a class disparity in the number of connections that are made and those that are not because of how social networks link people. Due to the computational impossibility of predicting every lost link in a network this size, the number of node pairs that should be employed for experimental assessment must be reduced. Because social networks are self-similar by nature, research done on a subset of the system may be applied to the whole system.
Applications of Link Prediction Techniques
Numerous application domains, including protein- protein interaction prediction, automatic hyperlink prediction, recommendation system construction, inferring complete networks from partial networks [13], detecting anomalous communications [14], predicting possible collaborators [15], and so on, are closely associated with link prediction.
Recommender Systems: A recommender scheme, also recognised as a commendation arrangement, is a sort of data mining arrangement that recommends a product to the consumer centred on the user’s past ratings or purchasing habits. Amazon, Flipkart, Myntra, and other commercial apps are the main uses for these platforms. Different link prediction algorithms are available for customized recommendations [16].
Medical Referral System: The procedure of sending patients to doctors with particular specializations is known as the medical referral system [17]. When a patient becomes unwell, they consult a general practitioner in different nations. The patient is sent to a specialist practitioner who specializes in the patient’s ailment type if the general practitioner is unable to resolve the condition. Finding the correct expert has gotten more difficult, though, as healthcare systems have grown. Finding the right specialist might take a long time at times, and this can have detrimental effects. Furthermore, patients could be directed to experts who are fully booked and unable to accept new patients. Link prediction has been used to forecast which specialists would likely receive recommendations in the future, which has helped to tackle the problem of medical referrals. Using SVM classifier for link prediction in medical referral systems, Almansoori et al. [17] achieved prediction accuracy of up to 92%.
Spam Mail Detection: Spam, often known as junk email, is any unsolicited email communication that is typically delivered in large quantities. Emails that are unsolicited by the recipient are known as spam. It’s critical to monitor traffic in a variety of security applications in order to spot any odd communication. Techniques for link prediction have been used to identify unusual vertices [18] and spam emails [19].
Community Discovery: The aim of community identification is to divide a whole social network into a collection of modules. These modules consist of clusters with extremely dense node connections [20][21]. Applications for community detection may be found in a number of areas, including product suggestion and review gathering. Many publications have employed link prediction algorithms for network evolution prediction and community discovery [22].
Privacy Control in Social Systems: The increasing usage of social media spots has made it more important than ever to discover reliable people. On these social networking sites, users frequently disclose a lot of personal and private information, including phone numbers, email addresses, and images. Making ensuring that data is protected from being exploited by any untrustworthy people is crucial. Link prediction tools are useful in identifying reliable individuals. This will protect user privacy on social media platforms. Aloufi [23] identified a local group of reliable individuals in a network by using link prediction algorithms.
Identifying Missing References in a Publication: Academic dishonesty and ethical violations are caused by plagiarism. Typically, an article has connections to a number of other articles. Some allusions, nevertheless, could be overlooked. Through the use of author and keyword matching, link prediction systems can assist in locating missing references within a publication [24].
Routing in Networks: Link prediction may be used to monitor traffic over many communication channels in a variety of security and network applications. In order to quickly discover communications those are odd (or aberrant) and warrant more examination, monitoring is necessary. In order to enhance routing efficiency, network applications can also utilize link prediction to find the best routes. Regular network outages have a negative impact on mobile communication quality. Weiss et al. [25] and Yadav et al. [26] suggested approaches for utilizing link prediction for routing in order to estimate signal strength. Hu and Hou [27] suggested traffic prediction methods to enhance packet routing in wireless networks.
Expert Detection: Research partnerships frequently provide high-quality outcomes. It might be challenging to locate a specialist researcher in one’s own field of expertise. Link prediction approaches may be employed in co-authorship networks to classify domain specialists given a network including several researchers and their relationships (in terms of co-authorship) working in distinct areas [28, 29]. Liu & Ning [30] ranked the applicants for high-level government positions using the link prediction approach.
Influence Detection: Analysing which users in the system have the greatest persuasive power is often crucial. For example, powerful customers can have a big impact on product sales. Link prediction algorithms were employed by Cervantes et al. [31] to classify the prominent nodes inside a specific system. In a comparable vein, Nguyen et al. [32] employ link prediction algorithms to determine a user’s impact and personality attributes.
Disease Prediction: Patients’ illnesses can be predicted via link prediction. Patients and disorders were arranged in a social network by Folino et al. [33]. The diseases are characterized as nodes in the system, and the simultaneous presence of two sicknesses in a patient is shown by an edge connecting them. The illnesses that might strike a patient given his present state of health are predicted via link prediction algorithms.
Literature Review
The first research discussed in this review is the major research aimed at similarity score based heuristics applied to link prediction in social networks. It then looks at machine learning-based methods which have gained immense traction to enhance accuracy of predictions. Other methods of link prediction used in the literature are also described to have a wider outlook of the field. Given that the majority of the available literature can be classified into the similarity- based and machine learning-based approaches, they are highlighted in the context of the review. Lastly, some areas of research gaps that have been noted amongst the existing literature are revealed to steer future developments in predicting social network links.
Similarity Score based Link Prediction Techniques
Some of the most important elements in the territory of online social systems are link prediction and suggestion. In recent decades, it has been a relevant area of study [34, 35, 36]. “Individuals You May Need to Employ” on LinkedIn, “You May Recognize” on Google+, and “Individuals You May Recognize” (PYMK) on Facebook are a few well-known instances of link prediction. Finding the similarity (or proximity) score between disconnected pairs of nodes is an essential first step in connection prediction. The recommendation of whether or not to recommend a connection to disconnected nodes is based on this score. The similarity score determines whether u and v are connected or not. A variety of link prediction techniques are available that govern the resemblance score among a given pair of nodes. These methods can be divided into groups according on various heuristics. Similarity- based link prediction techniques were divided into three groups by Martinez et al. [37]: local methods [38, 39, 40], global methods [41] and quasi-local methods [42]. To compute the resemblance mark among two nodes, local similarity score approaches rely on structural features based on the neighborhoods of the nodes [43]. When calculating similarity, these methods only consider neighbors that are directly shared. Common Neighbor, Jaccard Index, Salton Index, Adamic Adar Index, Preferential Attachment Index, Resource Allocation Index, and Sorensen Index are a few frequently used node neighborhood based local similarity score computation approaches [44, 45, 46]. Conversely, global approaches compute similarity by utilizing the chains of neighbors that exist between two nodes. This kind of similarity measurement technique has a high computing complexity and is very noisy. The Katz Index [47], SimRank [48], Blondel Index [49], and Global Leicht Holme Newman Index [50] are a few often used global similarity score heuristics. When calculating similarity, quasi-local approaches employ neighbors-of-neighbors or neighbors with limited lengths. Several frequently employed techniques for quasi-local similarity scores include local path index, friendlink and local random walks [51].
Local similarity score grounded approaches are the best extensively used of the three similarity calculation methods for online social network link prediction. These are straightforward in that they find the similarity score between disconnected node pairs using common shared properties, which are typically common shared nodes. Since these are the quickest link prediction methods, they can be used in large parallel applications. These methods also achieve low computational cost and good prediction accuracy [52]. An online community system is frequently treated as a graph for the purposes of experimental measurement and analysis. An edge (or link) in the network denotes the associations between the consumers, whereas a vertex in the graph represents each individual user. The presence and lack of linkages between the vertices are displayed visually via the adjacency matrix [53]. Increasing the total of relations between disconnected vertices in the given system is the primary goal of the link prediction technique. To determine a connection value among unconnected nodes, a variety of heuristics are employed by each link prediction technique. Local similarity score heuristics use node degree or the quantity of shared nodes as a criterion when calculating similarity scores. The network statistics serve as the main basis for selecting prediction methods.
The following is a summary of the prominent node neighborhood-based similarity score heuristics for link prediction:
1. Common Neighbors (CN): This metric calculates the closeness of two nodes in a given network by counting all of their shared neighbors. For collaboration networks, Newman [54] calculated the resemblance mark metric among two nodes by means of mutual neighbors. Equation 1 can be used to calculate the similarity score using Common Neighbors in the following way:
Where Tu and Tv stand for the group of nodes that a paired group of nodes, u and v, respectively, has as neighbors. When disconnected users, u and v, have a high similarity score at time instance t0, there is a strong likelihood that they will likely reconnect at time instance t1, where t0 <= t1.
2. Jaccard Index (JI): The Jaccard established the Jaccard Index (also recognized as the Jaccard Constant (JC)) more than a century ago, in 1901 [55]. The similarity over diversity is measured by this metric. In information retrieval, it is also known as a similarity metric. Equation 2 can be used to define the Jaccard Index as follows:
Based on the likelihood that a neighbor of node u or node v has a high chance of becoming a neighbor of nodes u and v, the resemblance mark is planned.
Researchers have used heuristics based on similarity scores in the past to identify likely relationships in a variety of applications. A link prediction algorithm constructed on keyword matching was suggested by Bhattacharya et al. [56]. The suggested method used text similarity to calculate the resemblance among node pairs. They discovered that the average similarity score drops as the amount of frequent common neighbors and keywords rises. They also discovered that, independent of the topological measures, user similarity ratings are comparable, with the exception of direct links. Zhou et al. [57] employed a variety of heuristics based on similarity scores to anticipate links across six distinct networks. Using various similarity score algorithms, they were able to achieve average performance up to 93.3% in footings of region below the ROC curve.
A summary of works on link prediction approaches based on similarity scores may be found in Table 2. Based on previous research on different similarity score heuristics for link prediction, we discovered that while a range of network topological property indices and link prediction approaches have been studied in the works; no study has looked at the relationship between topological property indices and link prediction approaches. Furthermore, we discovered that the methods currently in use for predicting links based on similarity scores either use node construction or node attribute information. No link prediction method that combines the use of node construction and profile data for link prediction is currently known to exist in the literature. Additionally, we found that threshold values are required for similarity score-based link prediction techniques in order to make decisions. It is challenging to determine the threshold value, nevertheless, at which link prediction can be carried out because huge social networks have a very dynamic structure. Every customer in an online social system has a unique combination of traits; therefore choosing a common cutoff point to determine if two detached users will reconnect is difficult for the entire social network (which has thousands of egos).
Table 2.
Different Techniques used for Similarity Score-based Link Prediction
| Author(s) | Year | Heuristic | Features | Dataset |
Best Performing Similarity Score Heuristic |
| Chen et al. [58] | 2005 |
Common Neighbor, Jaccard Index, Node Book Sales Preferential Attachment Adamic Adar Index, Neighborhood Index Preferential Attachment Index, Katz Index, Local Path Index | Node Neighborhood | Book Sales | Resource Allocation Index |
| Murata & Moriyasu [59] | 2007 | Common Neighbor, Adamic Adar Index, Preferential Attachment Index | Node Neighborhood | Yahoo! Chiebukuro | Adamic Adar Index |
| Song et al. [60] | 2009 | Common Neighbor, Adamic Adar Index, Preferential Attachment Index, Katz Index | Node Neighborhood Graph Distance | Flickr, Digg YouTube, MySpace Wikipedia LivJournal | Different heuristics for each dataset |
| Izudheen & Mathew [61] | 2016 | Common Neighbor, Jaccard Index, Adamic Adar Index, Preferential Attachment Index | Node Neighborhood | PPI (MINT) | Preferential Attachment Index |
| Lu et al. [62] | 2017 | Common Neighbor, Adamic Adar Index, Preferential Attachment Index, Katz Index | Node Neighborhood | MATADAOR | Common Neighbor |
| Tariq et al. [63] | 2019 | Common Neighbor, Jaccard Index, Adamic Adar Index | Node Neighborhood | Jaccard Index, Adamic Adar Index | |
| Hao Tian & Reza Zafarani [64] | 2020 | Common Neighbor variants, Jaccard Index | Proposed a γ-decay model generalizing neighborhood- based heuristics for improved link prediction in large networks. | Social and collaboration networks | γ-decay enhanced Common Neighbor |
| Tillman et al. [65] | 2020 | Extended CN, Jaccard Index, Preferential Attachment | Designed a unified heuristic framework for multiplex networks (multiple types of edges). | Scientific collaboration, trade, transportation | Proposed multiplex heuristic |
| Wang et al. [66] | 2020 | Motif-based Heuristic, CN, Adamic Adar | Combined local motifs with classical heuristics to capture higher-order structure. | Social, biological, academic networks | Motif-based heuristic |
| Govind Sharma et al. [67] | 2021 | CN, Adamic Adar | Studied higher-order relations affecting heuristic accuracy; analyzed bias in CN and AA. | Synthetic and real-world graphs | CN (noted to overestimate links) |
| Haji Gul et al. [68] | 2022 | Matrix-Forest Metric, CN, AA | Integrated local similarity and matrix-forest index to enhance prediction reliability. | Complex real-world networks | Matrix-Forest Metric |
| Yun et al. [69] | 2022 | Neo-GNN (heuristic-integrated) | Incorporated structural overlap heuristics (CN, Jaccard) inside GNN architecture for robustness. | Open Graph Benchmark (OGB) | Neo-GNN (heuristic-enhanced model) |
| Nirmaljit Singh & Ikvinderpal Singh [70] | 2023 | CN, AA, Resource Allocation, Preferential Attachment | Compared classical heuristics on wireless multiplex networks. | Wireless network datasets | Resource Allocation |
| Zhang et al. [71] | 2023 | Heuristic Learning GNN (HL-GNN) | Unified local/global heuristics through matrix-based GNN learning. | Planetoid, Amazon, OGB datasets | HL-GNN (learned heuristic model) |
| Y.V. Nandini et al. [72] | 2024 | Average Centrality Similarity | Combined degree, betweenness, closeness, and clustering centralities into a new similarity metric. | Real-world complex networks | Average Centrality Similarity |
| Puneet Kapoor et al. [73] | 2024 | Heuristic-based Feature Learning | Integrated heuristic and embedding features for heterogeneous networks. | Social, citation, biological networks | Learned hybrid heuristic features |
| Zhou, Wan & Du [74] | 2025 | Information Entropy Common Neighbor (IECNC) | Extended CN by including entropy to measure information uncertainty in neighborhoods. | Social and biological networks | IECNC (entropy- enhanced CN) |
| Pandey S.D. et al. [75] | 2025 | Strength Prominence (SP) Index | New similarity index combining tie strength and node prominence, works without common neighbors. | Fuzzy social networks | SP Index |
| La Cava et al. [76] | 2025 | Mixture of Experts (MoE-ML-LP) | Integrated multiple heuristic-informed experts for multilayer networks. | Real-world multilayer networks | MoE-ML-LP (ensemble heuristic model) |
Supervised Machine Learning Based Link prediction Methods
A cumulative similarity mark is calculated by similarity score established link prediction approaches using either communal shared attributes or the neighborhood of the node. When predicting missing links, it ignores the connectivity pattern between linked pairs. On the other side, machine learning centered link prediction approaches predict a class label based on the connection pattern among linked nodes (number of common neighbors or shared profile traits). Link prediction in online social systems can be viewed as a twofold machine learning classification challenge.
Hasan et al. [77] suggested using machine learning classification for absent link prediction in co-authorship systems as a resolution to the link prediction difficulty. Across two distinct co-authorship systems, a collection of supervised machine learning classification methods is applied to predict whether or not the two authors would collaborate on a paper in the future. This study examines two co-authorship networks: BioBase and DBLP. In a comparison of machine learning classifiers for link prediction, Hasan et al. [77] examined Decision Tree, SVM, KNN, Naïve Bayes, and Multilayer Perceptron. They discovered that all of these classifiers could solve the link prediction problem with a reasonable degree of accuracy. They did not, however, assess how well machine learning classifiers performed in comparison to several traditional similarity score algorithms. Benchettara et al. [78] expanded on Hasan et al.’s work for link prediction in the user-item purchase network of websites that engage in electronic commerce (E-Com). There is a bipartite graph in the E-Com network with two different kinds of nodes: users and products. If a user has bought an item, then the user and the item are connected. The use of an “indirect” feature for link prediction was demonstrated in the article. A feature for all users who bought a common item is the use of a similar item purchase count. It has been demonstrated that link prediction performance was enhanced by adding indirect features to the training set. O’ Madadhain et al. [79] utilized the logistic regression technique to forecast the likelihood of connections between various node pairings. They made use of network data gathered via emails from Enron, calls to AT&T, and articles from CiteSeer. Gong et al. [80] implemented link prediction utilizing support vector machine (SVM) technology on the Google+ website. Liu et al. [81] Using deep belief networks (DBN) for signed network missing link prediction. Every link in a signed network has a sign, either positive or negative. There is a positive indication on the edge between two users if they support or agree with each other. Conversely, there is a negative symbol on the edge between two users if they oppose or disagree with one another. They discovered that the effective prediction of link development in signed networks may be achieved through the application of deep belief networks. Scellato et al. [82] employed a variety of supervised learning methods for link prediction in location-based networks, including Naïve Bayes (NV), Random Forest (RF), Decision Tree (DT), and J48. For link prediction, they looked into place-based features like the overall number of common check-in locations, the percentage of common places between two users from all the places they have checked in, the total number of check-ins at a location, etc. If there are few check-ins, a common place is deemed to have high importance. The utilization of place information enhances the machine learning technique’s prediction ability, according to the findings of the scientists. Tasnádi & Berend [83] assessed the application of supervised machine learning algorithm for Yelp.com, a restaurant review platform. In the restaurant review network, they predicted links using greatest entropy.
Other Link Prediction Approaches
The problem of missing link prediction has been approached from a number of angles in the literature. Other methods of link prediction exist besides the widely used methods based on similarity scores and machine learning classifications. These include metrics based on social theory [84, 85], random walk based metrics [86, 87], probability graph based models [88], and so on. Kuo et al. [89] developed a framework for unsupervised link prediction using aggregative statistics. The two parts of the suggested framework are ranked-margin learning and inference method and a factor graph model. Zhang et al. [90] provided a study addressing the issue of social influence on Weibo.com, a microblogging social network. Users’ retweet behaviors are examined in ego networks using factor analysis and logistic regression to forecast potential future links.
Liu et al. [91] suggested a link prediction method based on three node centrality and weak ties. Degree, proximity, and betweenness centrality are the three centrality metrics that are employed. When calculating a similarity score, each common neighbor is given a different weight based on how important they are to the node’s relationship. To improve the prediction performance, the weak ties are considered.
Research Gaps
Link prediction is an essential job necessary to maintain the quick flow of information in social systems, according to a survey of the literature on the subject of link prediction approaches in online community systems. So, reducing the number of incorrect predictions without compromising the predictive ability of the underlying algorithms is crucial for enhancing the presentation of link prediction arrangements. The current body of literature has revealed the following research gaps on online social network link prediction:
Gap 1: Considerable research has been done on the topological characteristics of networks and link prediction methods based on similarity scores. Nevertheless, no previous research has connected the topological characteristics of the system with link prediction methods’ effectiveness.
Gap 2: Current methods for predicting linkages in online social networks either rely on network topology or node properties. When predicting links in online social networks, none of the link prediction methods currently in use took into account the combined properties of system arrangement and node properties. As a result, there isn’t a link prediction method that combines node properties and network structure for computing proximity scores.
Gap 3: Current link prediction methods assess the efficacy of similarity score-based link prediction methods using set threshold metrics. Every user’s network, however, has a unique connection pattern. Therefore, dynamic thresholding is required for link prediction.
Factors and Parameters Affecting the Missing Link Prediction in Social Network
Current link recommendation algorithms forecast each possible link’s linkage likelihood and suggest those with the highest likelihood. Therefore, the accuracy of link suggestion is the main emphasis of current approaches.
Every time advertising hits a Facebook user, Facebook Inc. gets paid. It makes sense that a suggested link, if it is created, encourages Facebook users to interact with one another and expand the audience for their ads, increasing Facebook Inc.’s income. The money generated by advertisements via a well- recommended and established link represents the value of link recommendation in this instance [92, 93, 94, 95].
Diversity is a key goal of connection commendation in addition to accurateness and utility, such as suggesting friends from different backgrounds to a user. Recommending links with diversity is advantageous for social networks overall as well as for individual members [96, 97].
However, link recommendation variety has not attracted much study interest despite these advantages. Firstly, measures for measuring the diversity of link suggestion must be designed. A variety of metrics have been put out to assess recommender system recommendation diversity. Since link recommendation uses a user-user graph while recommender systems utilize a user-item bipartite network, many of these metrics are not well suited to quantifying link recommendation variety. Here are some suggestions for creating metrics related to the diversity of link recommendations [98].
Conclusion
This review outlined the recent progress in the area of link prediction methods in the field of social network analysis and noted the increased importance by the connection of smart urban infrastructure. Even though great strides have been achieved by similarity- based heuristics and machine learning techniques, one still needs to improve on them to provide real time, scalable, and context sensitive prediction to make cities sustainable. The gaps in the current literature include the scarcity of work to combine network topology with node-level contextual features, the still use of fixed thresholding methods, and lack of literature to confirm the link-prescription performance in urban infrastructure and facility-management contexts. An improvement of such areas can contribute significantly to the improvement of the data-driven decision-making in smart buildings, intelligent transportation, resources optimization and the community- centric services. Altogether, the results confirm that social network link prediction may be a very important factor contributing to the enhancement of city sustainability, resilience, and effectiveness when it is appropriately adjusted to the requirements of smart city systems. Additionally, exploring link prediction for adaptive resource management and intelligent facility planning can enhance resilience and sustainability in next-generation smart cities.
