

Introduction
Literature Review
Problem Statement
Research Objective
Proposed Methodology
Dataset Collection
Data Preprocessing
Emotion-Neuroemotion Taxonomy Development
Lexicon Creation and Annotation
Neuroemotion-Informed Embedding Creation and Model Development
Results and Discussion
Conclusion and Future Scope
Introduction
Modelling the dynamics of human emotions is technically challenging. This is primarily because every human is unique, making emotional responses difficult to generalise. However, it is a well-known fact that human biology is common and can serve as a basis for studying the emotions of each individual. The current state-of-the-art models are trained primarily on vast amounts of text data, learning to represent words and phrases based on their co-occurrence and contextual usage. They are excellent at capturing semantic relationships like synonyms, antonyms, topic associations, and general sentiment polarity (positive, negative, neutral). However, they are not explicit models that are trained to capture and understand the underlying biological and physiological dimensions of raw emotion expressed in written text or any other form of communication. As a result, these models often struggle with classifying nuanced emotion states and sentiments. In a nutshell, the following are the main points of current algorithms used in this context [1].
•Subtle Emotional Differences: The nuanced distinctions between emotions, that is, the difference between joy and elation, sadness and grief, anger and frustration, can be flattened in embedding space. Models might capture that these are all positive or negative emotions, but fail to differentiate their specific qualities.
•Intensity of Emotions: Terms like ‘happy’ and ‘ecstatic’ may appear similar in embedding space despite differing in emotional strength.
•Physiological Basis of Emotion: The connection between linguistic expressions of emotion and the underlying hormonal and neurotransmitter activity is largely absent in standard embedding models. They don’t have access to or understanding of this biological layer. Standard embedding does not link linguistic expression with hormonal activity.
•Cultural and Individual Variations in Emotional Expression: Embedding overlooks how emotions are expressed differently across cultural dialects, such as in English. Hence, there is a need for better algorithms, including embeddings and classification, that are aware of emotion and human biology [2].
The following section, Literature, discusses the related work and research gaps. After the problem statement section. The data set description covers data collection, annotation of data, and neuroemotion taxonomy. The methodology section explains the embedding creation, model development, and hyperparameter tuning. Results and discussion present model performance and evaluation. The conclusion summarizes findings, highlights contributions, and suggests future research directions.
Literature Review
Humans interpret the world at varying levels of abstraction, which influences their perception of reality. Abstraction involves simplifying complex concepts into forms that can be easily grasped using prior knowledge and skills. For example, a biologist might view a flower in biological terms, while a poet might see it as a symbol of beauty and nature. Our perceptions and interpretations of the world are greatly influenced by our experiences, beliefs, and cultural origins.
Rural people, for instance, may have a different understanding of nature from city dwellers. Emotions can also be understood differently depending on the perspective from which they are seen. Emotions have biological roots in our neuroemotions and genetic composition. They show up physically as variations in respiration, heart rate, and facial emotions. Linguistically, emotions are expressed through language, with each culture and individual having their own emotional vocabulary. Philosophically, emotions can be studied to explore their nature, existence, and relationship to other concepts. In psychology, emotions are examined to understand their causes, effects, and roles in human behavior [3, 4]. Emotion states are broadly categorised as positive or negative depending on valence and intensity. The degree of abstraction at which we function, impacted by our own histories and experiences, ultimately determines how we see and comprehend emotions as well as the world at large [5]. The intricate system of emotions can be depicted in computer science as a conceptual framework or causal network model, in which nodes stand for various concepts (e.g., hormones, neurotransmitters, and emotions) and edges stand for the connections or influences among these concepts [5, 6].
The author of [7] summarizes a study that investigated the connections between money levels (perhaps referring to socioeconomic status), emotional traits, and aggressive behaviors in 56 girls aged 9 to 14 years. The study included participants from all five stages of a developmental framework, though the specific framework is not mentioned in the provided text.
At the same time, emotions as a network of sub- processes are often used in contexts including causal networks: A Bayesian network shows how neurotransmitters influence hormones an approach. The biopsychosocial model is generally used in psychology and neuroscience to explain how biological factors (like neurotransmitters and hormones) interact with psychological states (like emotions) [7, 8]. The current understanding of [9] where emotions come from is different from older ideas that treat emotions and emotional feelings as completely separate things [10]. Some people believe that the feelings we get from emotions are separate from the brain and body activities related to emotions. Another older idea [11], suggested that the body’s reactions must happen before we can feel emotions. But the new view says that our emotional feelings are just a part of the brain and body activities happening during an emotion. In other words, our feelings are the result of natural, unlearned processes in the brain. Emotion sensation is a phase of neurobiological activity detected by the organism [12]. Emotional feeling, like any other neurobiological activity, varies from low to high levels of intensity. The autonomic nervous system may modulate the emotion feeling but does not change its quality or valence [13].
To investigate how hormones affect emotional processing, it is necessary to understand how these hormones are administered and how this alters natural hormone levels that influence cognition. The manner of injection is critical because it influences how much hormone enters the brain and the processing of facial expressions [14]. Research indicates that the emotional aspect of feelings has played a significant role in the development of consciousness and influences our emotional responses, thought processes, and actions related to achieving goals. The recent study [15] shows that emotion-aware AI systems integrate multimodal signals like facial expressions, voice, and text to better interpret and respond to human emotions. This approach aims to improve psychological well-being and foster a deep global human connection to empathetic machine interaction. Contemporary research also shows that there are additional mathematical models and theoretical frameworks that are considered to represent a problem of emotion modeling. The dynamical systems theory models how systems evolve over time under the influence of internal and external factors. For example neurotransmitters, hormones, and emotions could be seen as components of a dynamical system where changes in one component (e.g., an increase in cortisol) lead to changes in others (e.g., heightened stress or anxiety [16, 17]. The cognitive- affective personality system (CAPS) is a psychological framework that explains how individual personality differences arise from the interaction of cognitive and emotional factors [18]. An emotion model can represent how neurotransmitters and hormones modulate different emotional responses, consistent with this theory. Model-based on the homeostatic regulation models are those models that describe how biological systems maintain stability (homeostasis) through feedback loops [19, 20]. Author [21] proposed an AI-driven mental health system that integrates facial emotions, a chatbot, and a voice bot to deliver real-time, personalised emotion support and enhance psychological resilience.
Problem Statement
Sentiments and feelings are not simply abstracted semantic constructs but are biologically-anchored phenomena formed in human physiology, lived experiences, and neuroemotion reactions (e.g. serotonin, dopamine, cortisol). Smart Urban Systems, designed to address detailed modeling of population dynamics and their relation to public health, urban safety, and community interactions, are especially challenged in computational frameworks at scale. Contemporary embedding models excel at semantic relations (synonymy, sentiment polarity) but do not encode emotion-specific non-cognitive states linked to neuroemotion signatures, and are thus inadequate as proxies for human emotions and for emotion-aware urban analytics.
Designed for Smart Urban Systems, the model prioritizes accuracy in classifying emotions tied to stressors like urban density, socio-economic disparities, and crisis events—factors pivotal to urban governance, sustainable urban development, and adaptive city planning. and adaptive city planning. By anchoring emotion representation in neuroemotion principles, the classifier advances urban-scale applications in mental health monitoring, crowd behavior prediction, and public policy design, ensuring computational models mirror the biological realism of human emotion dynamics.
i. Traditional Embedding Space
Let E ⊆ be the traditional embedding space where:
v(w)∈ E represents the vector embedding of word w
d is the dimensionality of the embedding space
sim(, ) represents semantic similarity between vectors
ii. Emotion - Biological State Space
Let B be the biological space where:
N = {, , ... , } represents the set of neurotransmitter levels
: serotonin level
: dopamine level
: norepinephrine level
H = {, , ... , }represents the set of hormone levels
: oxytocin level
: adrenaline level
Thus, b(t)∈ B represents the biological state at time t:
b(t) = [N(t), H(t)]
iii. Emotion Function
Represents mapping from biological state to emotion space E’, where: E’ represents the true emotion space
represents the emotional state induced by biological state b(t)
iv. Current Limitations
For traditional embedding models f: Text → E:
∈ E' such that:
sim(f(), f())≈1 but
This represents that semantically similar words may correspond to vastly different biological/emotional states.
v. Proposed Solution
Define classifier C: Text × B → Y where:
Y is the set of emotion labels
C should minimize:
L = ∑
Where:
x is the input text
b is the biological state
y is the true emotion label
e is the expressed emotion
𝜆 is a regularization parameter
Where , are threshold parameters.
Research Objective
Construct an enhanced embedding of existing models to map emotion-biological spaced vectors and evaluate the classifier as a downstream task.
Proposed Methodology
The section begins with an explanation of how the dataset was created. For better knowledge of the workflow of the paper, kindly refer Figure 1 workflow of the study.
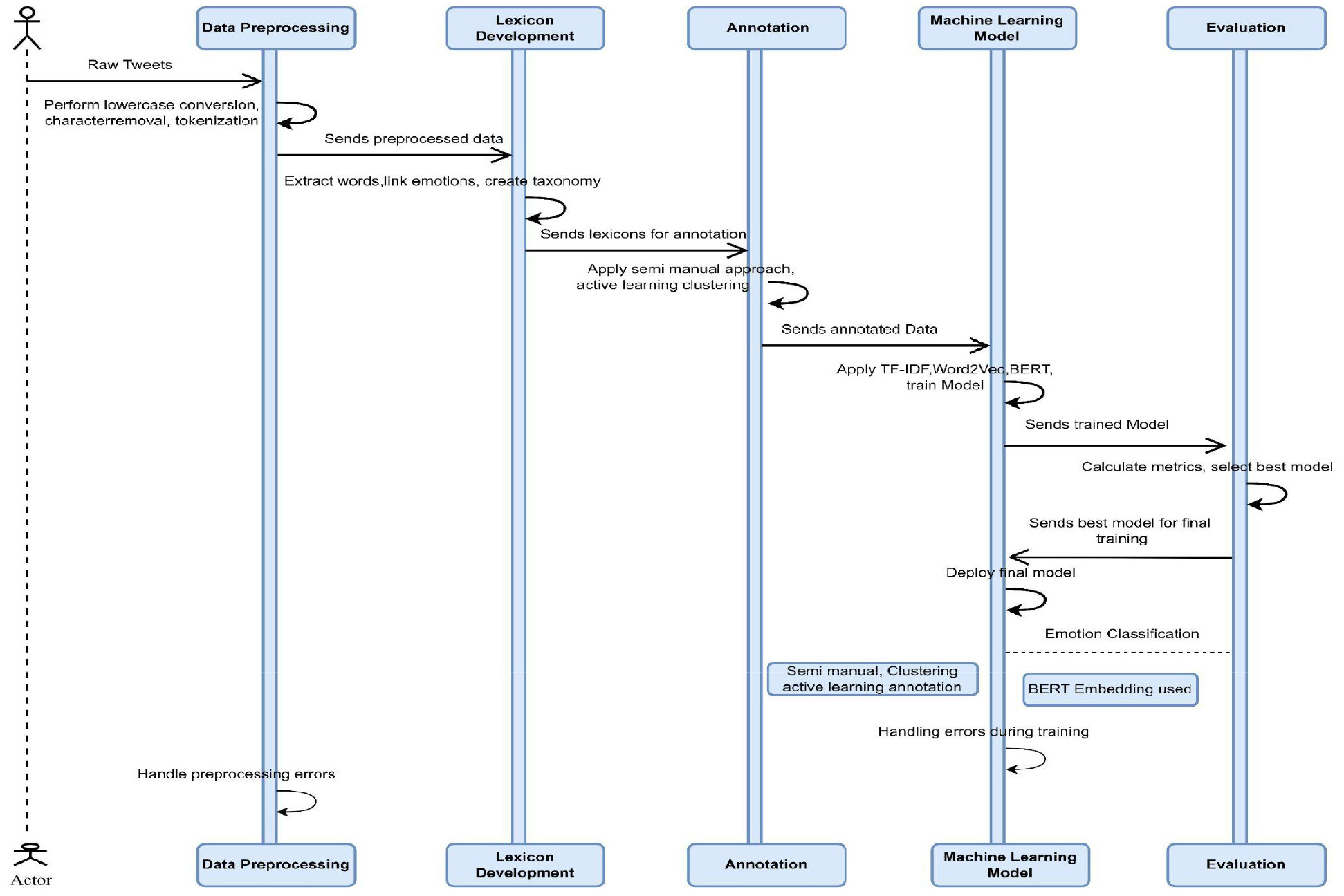
Dataset Collection
The first step to providing the solution is to build a Hinglish dataset of tweets in which the users discuss topics such as urban living, and classify emotions and so on.
Data collection starts by collecting data from the Twitter API, which is a tool that allows users to access and gather large amounts of data related to specific domains, seed words, hashtags, and topics related to war, conflict, and tragedy. This step is crucial for obtaining a rich dataset that reflects a wide range of emotions expressed by the user on the required topic. Later on, using the initial corpus collected, the search filters (vocabulary) were expanded. We also implemented pre-processing techniques to remove irrelevant tweets and ensure the dataset is focused on the target emotional states, and finally, organized and stored the collected tweets in a structured format within the database. Hence, a total of 19,020 tweets were collected for this purpose [19, 20, 21, 22]. The process of building, refining, and automating machine learning models with an encoded dataset to classify emotions automatically [23]. It is noteworthy that this part has been divided into subsections. Once the annotation was complete, various classification models were built to evaluate emotion detection accuracy and optimise recall-precision balance. Although the study focuses on BERT and LightGBM baseline models, including Logistic Regression, SVM, Random Forest, and Gradient Boosting, were also treated as benchmark models for effectiveness. The suggested method started by creating a base code structure, enabling experimentation and testing with different pipelines.
Data Preprocessing
Cleaning of data involved necessary pre-processing operations like lowercase conversion, special character removal, tokenization, and stopword removal. For vectorization, TF-IDF was selected over simpler and more sophisticated techniques like Bag of Words because it better captures the context of emotional utterances when dealing with Hinglish data. Other techniques like word embeddings (e.g., Word2Vec) were not taken into consideration in this stage due to their higher computational complexity, cost, and requirement for more thorough tuning. For several reasons, a particular set of models was chosen, like Naive Bayes, Random Forest, Support Vector Machine (SVM), Gradient Boosting, and Logistic Regression. To begin with, these algorithms are renowned for their dependability and efficiency in the text classification task. Naive Bayes and Random Forest are strong baseline models that often perform well in high-dimensional spaces, like those created by TF-IDF vectors. Random Forest and Gradient Boosting were included due to their ability to capture non-linear relationships and handle noisy data effectively, which is crucial when dealing with the variability in Hinglish emotional utterances. Naive Bayes, while a simpler model, is particularly effective in handling text data due to its probabilistic nature and computational efficiency. Deep learning models (e.g., LSTM, BERT) were not taken into consideration because they require large datasets and higher computational resources and the need of extensive hyperparameter tuning. These constraints made them less suitable for all resource settings.
Emotion-Neuroemotion Taxonomy Development
In this step, a taxonomy was developed for linking specific emotions (e.g., fear, stress, love) to their corresponding neurotransmitters (e.g., serotonin, dopamine) and hormones (e.g., cortisol, oxytocin) and also cross-referenced with the established biological framework. This taxonomy is informed by established psychological and neuroscientific literature, aligning effective states with biochemical triggers involved in emotional regulation. The taxonomy supports emotion- aware analytics in Smart Urban Systems and contributes to mental health-informed urban development and sustainable social study, as shown in Table 1.
Table 1.
Hyperparameters selected for the classification model
Lexicon Creation and Annotation
Keywords and phrases extracted are frequently used on Twitter to express target emotions. A full, comprehensive guide was made on annotation, and samples on how to do labeling were provided. In due process, the lexicon expansion in Table 2 is shown as we continuously updated the lexicon as new emotional expressions and slang terms emerged on Twitter. For annotation following methods are used as it is a complex task of mapping emotions.
i. Semi-Manual Annotation: Human annotators label data to improve accuracy [24].
Table 2.
Lexicon Expansion Workflow
ii. Active Learning: Select the most informative data points for labeling [25, 26, 27].
iii. Clustering: Group similar tweets to streamline the annotation process. For maintaining the quality and accuracy of the lexicon and mappings, the process was done interactively with humans in a loop [28, 29]. Continuously updated the lexicon as new emotional expressions emerge. Numerically, here are the evaluation results in Table 3:
Table 3.
Evaluation Results
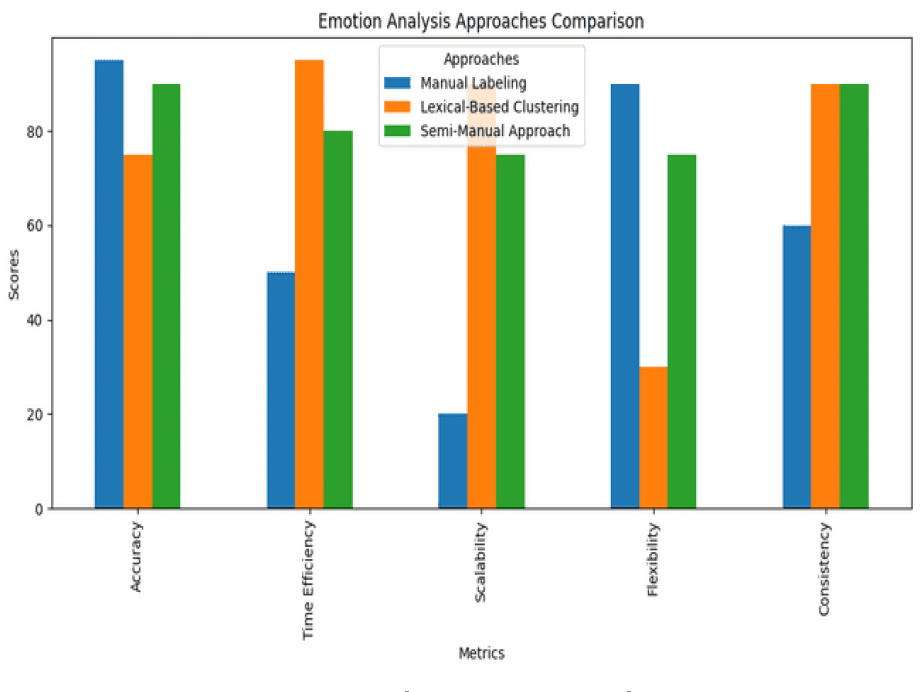
Using this approach of using all three methods , it can be inferred that choice of method clearly depends on the specific requirements and purpose. If accuracy is the top priority, Manual Labeling is the most appropriate choice. If scalability and efficiency are more important, Lexical-Based Clustering should be used. However, if a balance between accuracy, efficiency, scalability, and flexibility is desired, the Semi-Manual Approach is the most suitable method.
Further, in this phase, the logic to capture the nuances of emotions and the intricacies of the Hinglish language was developed. This module processes symbolic rules that encode the relationships between emotions and their underlying neuroemotional processes. The process involved defining and discovering symbolic rules that govern the interplay between specific emotions, neurotransmitters, and hormones. Technically, a Python module to integrate these logical conditions for creating data encoded with symbolic rules was developed. These rules were tested to ensure they correctly infer the relationships between emotional language and neuroemotional signatures during the annotation process.
Our research followed a semi-automatic approach, where an initial set of tweets was labeled to define and discover rules regarding the emotional pathway (including biological and expressive manifestations in language). Then we tried the active learning and transferring approach, and finally, we also experimented with expanded lexicon-based clustering for annotation. From Figure 2 it can clearly be observed that the dataset annotation process involved comparing three different approaches: Manual Labeling, Lexical- Based Clustering, and a Semi-Manual Approach. Each of these methods was evaluated across five key metrics: Accuracy, Time Efficiency, Scalability, Flexibility, and Consistency. Using this approach of using all three methods , it can be inferred that the choice of method clearly depends on the specific requirements and purpose. If accuracy is the top priority, Manual Labeling is the most appropriate choice. If scalability and efficiency are more important, Lexical-Based Clustering should be used. However, if a balance between accuracy, efficiency, scalability, and flexibility is desired, the Semi-Manual Approach is the most suitable method. Henceforth, once these annotations were complete, the identification of emotional classes is done.
To create enhanced embeddings that combine linguistic and neuroemotion features, the workflow begins by mapping emotional states to their corresponding neuroemotion signatures. This process uses the emotion- neuroemotion taxonomy developed earlier in the study, which links specific emotions (e.g., stress, love, fear) to neurotransmitters (e.g., serotonin, dopamine) and hormones (e.g., cortisol, oxytocin). The neuroemotion signature corresponding to each tweet in the dataset is extracted by utilizing the emotional label that corresponds to it during the annotation phase. Next, these neuro-emotional characteristics are learned and fed back to the BERT embedding, which is capable of providing a dual-text semantics representation of the text, not only representing the linguistic context of the word within the representation but also the biological background. It gives a numerical vector to each neuroemotion signature, whose each dimension corresponds to one of the neurotransmitters/hormones. The vectors are normalized, which makes the comparison possible between different scales. Concatenating the BERT embeddings of each tweet with the Neuroemotion vector creates an integrated representation. The improved embedding is used as an input by machines such as LightGBM.
Neuroemotion-Informed Embedding Creation and Model Development
Linguistic and neuroemotion features were combined to enhance the semantic representation of the emotional utterances. For each annotation tweet, the corresponding emotional label was mapped to the vector presentation based on the taxonomy described in Table 1. Each Neuroemotion vector was six- dimensional, with each dimension representing a normalized score of 0 and 1, corresponding to specific neurotransmitters: serotonin, dopamine, cortisol, oxytocin, norepinephrine, and adrenaline. These values were derived using the rule-based logic during annotation, assigning 1 for presence, 0 for absence, and a fraction value for four crescents. To map emotional states into their corresponding Neuroemotion signatures, the workflow starts by. It takes advantage of the emotion-neuroemotion taxonomy developed in the preceding sections, a system that connects specific emotions (e.g., stress, love, fear) to particular neurotransmitters or hormones (e.g., serotonin, dopamine, cortisol, oxytocin). From the annotated data from each tweet, the meuroemotion record associated with the given emotional label is retrieved. After that, these neuro-emotional characteristics are included in the pre-trained BERT embeddings to provide a more accurate representation of the text that takes into account both its biological foundations and linguistic context. Every Neuroemotion signature is shown as a number vector, with each dimension denoting a distinct hormone or neurotransmitter. These vectors are normalized to ensure consistency across different scales. Next, the Neuroemotion vector is concatenated with the BERT embeddings for each tweet, forming a unified representation. BERT captures rich contextual nuances in Hinglish text, while LightGBM handles high-dimensional features and avoids overfitting. Their combination leverages deep semantics with scalable, interpretable classification. This enhanced embedding serves as the input for machine learning models, such as LightGBM.. In this section, we begin the construction of emotion-aware classifiers. Followed by a comparative study.
With an accuracy of 0.971429, an F1 score of 0.96977, and an AUC of 0.998671, Random Forest emerged as the top-performing model, indicating strong overall performance. However, despite these impressive results, the scope of the study is expanded for several key reasons.
Robustness was the first critical concern. To ensure that the final model would generalize effectively across different subsets of data and variations in text representation, even though Random Forest performed well on the dataset. Second, to explore more state- of-the-art techniques given the rapid advancements in NLP and emotion classification. Algorithms like XGBoost and LightGBM have become increasingly popular in text classification due to their ability to handle complex data interactions and improve model performance.
Second, while Random Forest worked well with Neuroemotion-Informed BERT embeddings, there is a need to investigate how other advanced algorithms might leverage these rich representations. BERT embeddings encode intricate contextual information, and algorithms like XGBoost and LightGBM might be able to capture even more nuanced patterns that Random Forest could overlook. These ensemble models are also highly adaptable and can offer gains in both accuracy and generalization.
Third, the potential of deep learning models despite initial setbacks with BiLSTM is considered. Deep learning architectures have shown great promise in capturing sequential and local patterns in text, which are often missed by traditional models.
Fourth, computational efficiency was also an issue. While Random Forests delivered good results, in large data sets, for example LightGBM algorithm software is well-known highest performance and fastest advantage. Faster algorithms will be preferable for future scalability and potential real-time applications- -as long as they do not sacrifice performance.
Finally, the step is to balance interpretability with performance. It is possible that Random Forest may not capture all of the complexity of the dataset, although it may be interpretable to some extent.
Scalability and potential real-time applications may benefit from faster algorithms without compromising performance.
Lastly, the trade-off between performance and interpretability is considered. Even while Random Forest may be somewhat interpreted, it might not adequately represent the dataset’s complexity. Even though deep learning models are regarded as “black boxes,” they may provide notable performance gains that, in some use situations, such as identifying subtle emotional states in Hinglish text, might outweigh the need to sacrifice interpretability.
Results and Discussion
After training the models, several evaluation metrics were used to see how accurately they can directly classify the data. These steps are key to recognizing limitations in the model and investing accordingly to achieve the desired output. The trained model is then used to classify the emotions. The system can then automatically detect and analyze the emotional tone in hinglish tweets, enabling automated emotion-aware analysis for urban scenarios.
Taking all these factors into consideration, experiments were conducted with multiple models: Logistic Regression, Support Vector Machine (SVM), Random Forest, Gradient Boosting, XGBoost, LightGBM, While each model was tested with its variants and architectures, except for CNN, and tested three different text representation methods on the other four models: TF-IDF, Word2Vec (w2v), and BERT (the two best). While other models were evaluated, the BERT, LightGBM pipeline demonstrated the best balance of scalability, performance, and contextual accuracy, making it the optimal architecture for an emotion-aware smart urban system. The approach, which carried out tasks as shown above, enabled us to examine the relative merits of the four different models from lots of perspectives and determine the best one. Table 4 presents a detailed performance comparison across models using accuracy, F1-score and AUC as key indicators.
Table 4.
Performance Evaluation of Classification Model
From Table 4, it can be seen that LightGBM with BERT embeddings is the best model. It was able to obtain 98.57% accuracy, 0.9855 F1 score, and 1.0 AUC. This combination did better than others because LightGBM is good with lots of data, and BERT understands text well. BERT made all models do better than TF-IDF and Word2Vec, showing it’s good for this task. Gradient Boosting and LightGBM did well, especially with BERT. Logistic Regression and SVM were also good with TF-IDF and BERT. Table 5 presents the representation and corresponding training time and reference time of the different models.
Table 5.
Inference Time of Different Models
TF-IDF models were faster but not as good. Overall, BERT was the best, followed by Word2Vec and then TF-IDF. However, TF-IDF was faster to use. Most models have over 90% accuracy, so this task can be done well in different ways. Figure 3 compares the performance of models using accuracy, F1 score and AUC of various machine learning models using accuracy, F1 score, and AUC metrics. These models range from approximately 0.89 to 0.98. The main observation is that models utilizing the BERT representation tend to achieve high accuracy. Compared to those using TF-IDF and Word2Vec, among all. The Gradient Boosting models, those with LightGBM with BERT representation, stand out, achieving an accuracy of 0.98 and an F-score of 0.985. Additionally, BERT consistently outperforms the other representation techniques across various models, although the accuracy varies slightly across the different models and representations. BERT consistently provides better results, making it the most effective representation technique. LightGBM with BERT was best because it handles lots of data well and understands text. It took longer (276.86s) but did well. Gradient Boosting with BERT was second best (97.14% accuracy). It’s good with complex data and BERT helps it understand text. But it took very long (721.64s). Logistic Regression with TF-IDF did surprisingly well (94.29% accuracy) and was fast (6.36s). It works well for this task, maybe because the data is simple enough for it. SVM with TF-IDF did well (95.71% accuracy) and was fast (1.87s). SVM is good at finding patterns in TF-IDF data. Random Forest with Word2Vec didn’t do as well (92.86% accuracy).
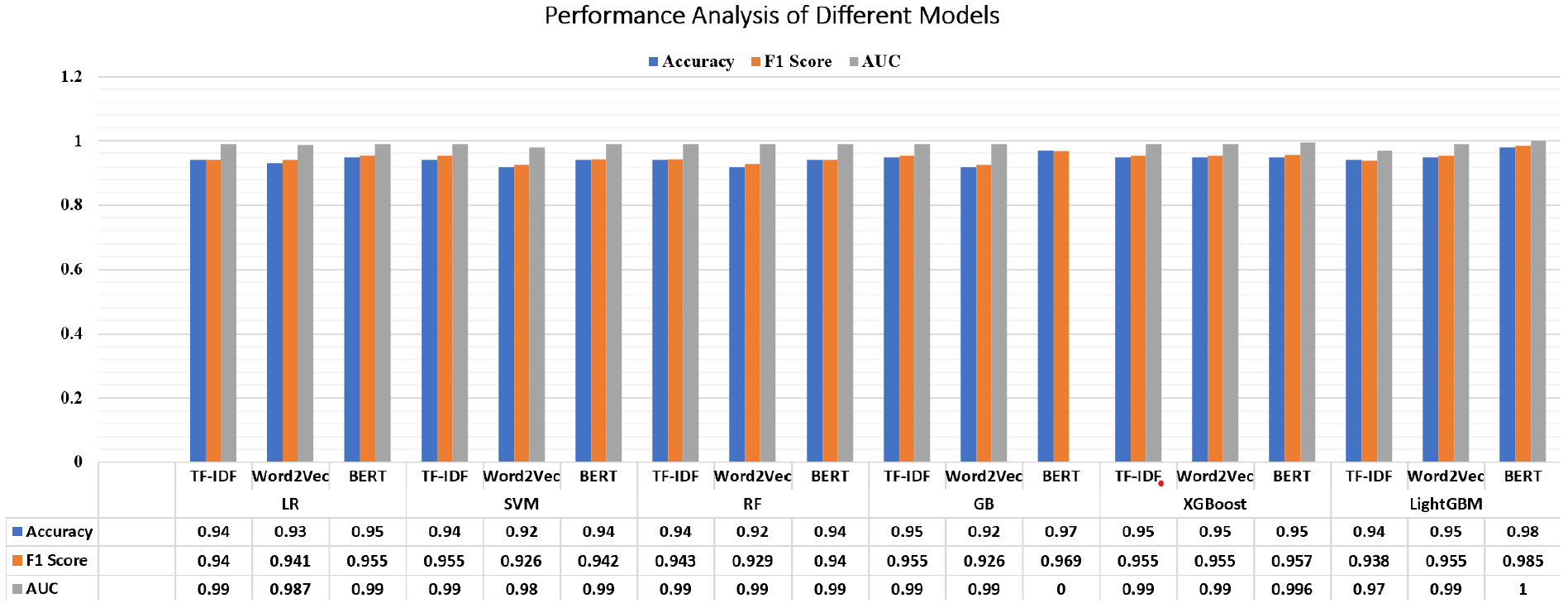
Our findings show that strong methods like Light GBM or Gradient Boosting, when used with BERT embedding, work best for this task. But simpler models with TF-IDF can be good too and are faster.
Conclusion and Future Scope
The NeuroEmotion classifier demonstrates the viability of Neuroemotion-informed AI frameworks for Smart Urban Systems, particularly in crisis response and urban governance or community sentiment analysis. By combining semi-automated annotation (kappa = 0.85) with LightGBM and BERT embeddings (98.57% accuracy), the system enables scalable, emotion-aware urban analytics critical for real-time monitoring of public distress in conflict zones or disaster scenarios and urban regeneration initiatives. BERT embeddings effectively capture contextual nuances essential for sustainable urban development, such as identifying localized emotional hotspots or informing emergency resource allocation through AI-enhanced public policy support. While computational trade-offs exist—BERT-based models require longer training times—their accuracy advantages align with the precision demands of sustainable Smart Urban Systems tasked with safeguarding public well-being. Other models such as Gradient Boosting and SVM variants (95.71-97.14% accuracy), offer faster alternatives for time-sensitive urban workflows, such as rapid sentiment dashboards for city administrators.
Despite its high accuracy and generalisability, the suggested approach still has several drawbacks. The classifier’s applicability in other multilingual or low- resource situations may be impacted by the decreased linguistic scope caused by the usage of Hinglish tweets. Although neuroemotion mapping offers interpretability, its biological abstraction may not represent the whole range of human affective expression. Another constraint, particularly with BERT-based structures, is computational expense. For smart city systems, future research might use multimodal signals like speech, picture, or biometric data streams to improve the accuracy of emotion recognition and practicality and integration into Smart Urban Systems can leverage these models to dynamically optimize public health interventions, support sustainable community design, and foster emotionally resilient populations—key pillars in sustainable social studies and life cycle- aware urban design.
The Neuroemotion Classifier, a ground-breaking framework created for Smart Urban Systems, is the novelty of this study. Classifier classifies emotions in social media by combining language patterns and neurochemical processes. By using neuroemotion- informed BERT embeddings and a unique emotion- neuroemotion taxonomy, it does this, combining computational linguistics with neurobiological insights. With this method, a more thorough and biologically based understanding of human emotion can be gained that can be applied to crisis management, urban resilience, and community well-being.
In conclusion, this research validates the efficacy of combining advanced embedding techniques such as BERT with ensemble methods for emotion classification in social media text. This approach offers potential applications for sustainable smart building technologies, including real-time emotion monitoring during crises, providing valuable insights for sustainable crisis management, mental health, and urban development support systems. For future work, it is recommended that more emotional mapping with sustainable building data and large multimodal datasets be conducted to enhance the system’s scalability and impact on urban design and governance.
